
By Ishan Shah
Initially, we were using machine learning and AI to simulate how humans think, only a thousand times faster! The human brain is complicated but is limited in capacity. This simulation was the early driving force of AI research. But we have reached a point today where humans are amazed at how AI “thinks”. A quote sums it up perfectly, “AlphaZero, a reinforcement learning algorithm developed by Google’s DeepMind AI, taught us that we were playing chess wrong!”
While most chess players know that the ultimate objective of chess is to win, they still try to keep most of the chess pieces on the board. But AlphaZero understood that it didn’t need all its chess pieces as long as it was able to take the opponent’s king. Thus, its moves are perceived to be quite risky but ultimately they would pay off handsomely.
AlphaZero understood that to fulfil the long term objective of checkmate, it would have to suffer losses in the game. We call this delayed gratification. What’s impressive is that before AlphaZero, few people thought of playing in this manner. Ever since various experts in a variety of disciplines have been working on ways to adapt reinforcement learning in their research. This exciting achievement of AlphaZero started our interest in exploring the usage of reinforcement learning for trading.

This article is structured as follows. The focus is to describe the applications of reinforcement learning in trading and discuss the problem that RL can solve, which might be impossible through a traditional machine learning approach. You won’t find any code to implement but lots of examples to inspire you to explore the reinforcement learning framework for trading.
- What is reinforcement learning?
- How to apply reinforcement learning in trading?
- Components of reinforcement learning
- Q Table and Q Learning
- Key Challenges
What is reinforcement learning?
Reinforcement learning might sound exotic and advanced, but the underlying concept of this technique is quite simple. In fact, everyone knows about it since childhood!
As a kid, you were always given a reward for excelling in sports or studies. Also, you were reprimanded or scolded for doing something mischievous like breaking a vase. This was a way to change your behaviour. Suppose you would get a bicycle or PlayStation for coming first, you would practice a lot to come first. And since you knew that breaking a vase meant trouble, you would be careful around it. This is called reinforcement learning.
The reward served as positive reinforcement while the punishment served as negative reinforcement. In this manner, your elders shaped your learning. In a similar way, the RL algorithm can learn to trade in financial markets on its own by looking at the rewards or punishments received for the actions.
Like a human, our agents learn for themselves to achieve successful strategies that lead to the greatest long-term rewards. This paradigm of learning by trial-and-error, solely from rewards or punishments, is known as reinforcement learning (RL)
- Google Deepmind
How to apply reinforcement learning in trading?
In the realm of trading, the problem can be stated in multiple ways such as to maximise profit, reduce drawdowns, or portfolio allocation. The RL algorithm will learn the strategy to maximise long-term rewards.
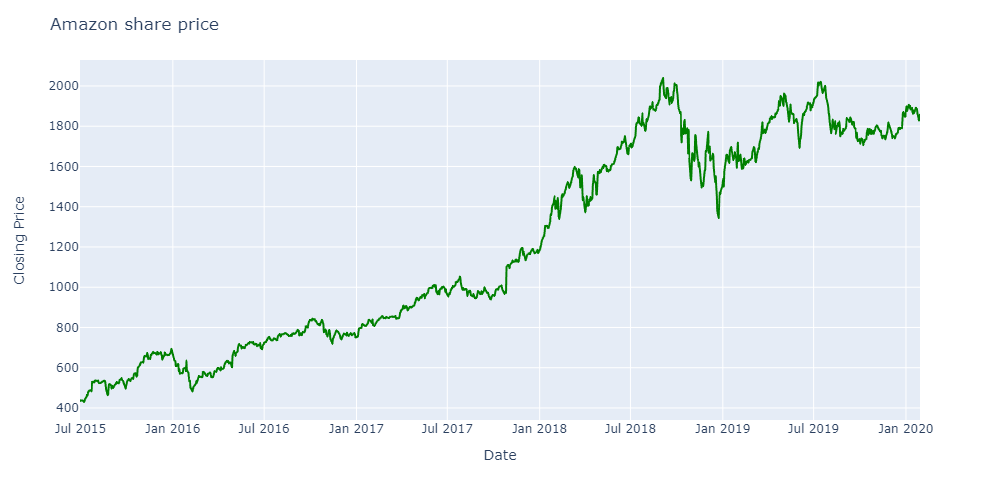
For example, the share price of Amazon was almost flat from late 2018 to the start of 2020. Most of us would think a mean-reverting strategy would work better here.

But if you see from early 2020, the price picked up and started trending. Thus from the start of 2020, deploying a mean-reverting strategy would have resulted in a loss. Looking at the mean-reverting market conditions in the prior year, most of the traders would have exited the market when it started to trend.
But if you had gone long and held the stock, it would have helped you in the long run. In this case, foregoing your present reward for future long-term gains. This behaviour is similar to the concept of delayed gratification which was talked about at the beginning of the article.
The RL model can pick up price patterns from the year 2017 and 2018 and with a bigger picture in mind, the model can continue to hold on to a stock for outsize profits later on.
How is reinforcement learning different from traditional machine learning algorithms?
As you can see in the above example, you don’t have to provide labels at each time step to the RL algorithm. The RL algorithm initially learns to trade through trial and error and receives a reward when the trade is closed. And later optimises the strategy to maximise the rewards. This is different than traditional ML algorithms which require labels at each time step or at a certain frequency.
For example, the target label can be percentage change after every hour. The traditional ML algorithms try to classify the data. Therefore, the delayed gratification problem would be difficult to solve through conventional ML algorithms.
Components of reinforcement learning
With the bigger picture in mind on what the RL algorithm tries to solve, let us learn the building blocks or components of the reinforcement learning model.
- Action
- Policy
- State
- Rewards
- Environment
Actions
The actions can be thought of what problem is the RL algo solving. If the RL algo is solving the problem of trading then the actions would be Buy, Sell and Hold. If the problem is portfolio management then the actions would be capital allocations to each of the asset classes. How does the RL model decide which action to take?
Policy
There are two methods or policies which help the RL model take the actions. Initially, when the RL agent knows nothing about the game, the RL agent can decide actions randomly and learn from it. This is called an exploration policy. Later, the RL agent can use past experiences to map state to action that maximises the long-term rewards. This is called an exploitation policy.
State
The RL model needs meaningful information to take actions. This meaningful information is the state. For example, you have to decide whether to buy Apple stock or not. For that, what information would be useful to you? Well, you can say I need some technical indicators, historical price data, sentiments data and fundamental data. All this information collected together becomes the state. It is up to the designer on what data should make up the state.
But for proper analysis and execution, the data should be weakly predictive and weakly stationary. The data should be weakly predictive is simple enough to understand, but what do you mean by weakly stationary? Weakly stationary means that the data should have a constant mean and variance. But why is this important? The short answer is that machine learning algorithms work well on stationary data. Alright! How does the RL model learn to map state to action to take?
Rewards
A reward can be thought of as the end objective which you want to achieve from your RL system. For example, the end objective would be to create a profitable trading system. Then, your reward becomes profit. Or it can be the best risk-adjusted returns then your reward becomes Sharpe ratio.
Defining a reward function is critical to the performance of an RL model. The following metrics can be used for defining the reward.
- Profit per tick
- Sharpe Ratio
- Profit per trade
Environment
The environment is the world that allows the RL agent to observe State. When the RL agent applies the action, the environment acts on that action, calculates rewards and transitions to the next state. For example, the environment can be thought of as a chess game or trading Apple stock.
RL Agent
The agent is the RL model which takes the input features/state and decides the action to take. For example, the RL agent takes RSI and past 10 minutes returns as input and tells us whether we should go long on the Apple stock or square off the long position if we are already in a long position.
Let’s put everything together and see how it works.

Step 1:
State & Action: Suppose the Closing price of Apple was $92 on July 24, 2020. Based on the state (RSI and 10-days returns), the agent gave a buy signal.
Environment: For simplicity, we say that the order was placed at the open the next trading day, which is July 27. The order was filled at $92.Thus, the environment tells us that you are long one share of Apple at $92.
Reward: And no reward is given as we are still in the trade.
Step 2:
State & Action: You get the next state of the system created using the latest price data which is available. On the close of July 27, the price had reached $94. The agent would analyse the state and give the next action, say Sell to environment
Environment: A sell order will be placed which will square off the long position
Reward: A reward of 2.1% is given to the agent.
|
Date |
Closing price |
Action |
Reward (% returns) |
|
July 24 |
$92 |
Buy |
- |
|
July 27 |
$94 |
Sell |
2.1 |
Great! We have understood how the different components of the RL model come together. Let us now try to understand the intuition of how the RL agent takes the action.
Q Table and Q Learning
Q table and Q learning might sound fancy, but it is a very simple concept.
At each time step, the RL agent needs to decide which action to take. What if the RL agent had a table which would tell her which action will give the maximum reward. Then simply select that action. This table is Q-table.
In the Q-table, the rows are the states (in this case, the days) and the actions are the columns (in this case, hold and sell). The values in this table are called the Q-values.
|
Date |
Sell |
Hold |
|
23-07-2020 |
0.954 |
0.966 |
|
24-07-2020 |
0.954 |
0.985 |
|
27-07-2020 |
0.954 |
1.005 |
|
28-07-2020 |
0.954 |
1.026 |
|
29-07-2020 |
0.954 |
1.047 |
|
30-07-2020 |
0.954 |
1.068 |
|
31-07-2020 |
0.954 |
1.090 |
From the above Q-table, on 23 July, which action would RL agent take? Yes, that’s right. A “hold” action would be taken as it has a q-value of 0.966 which is greater than q-value of 0.954 for Sell action.
But how to create the Q-table?
Let's create a Q-table with the help of an example. For simplicity sake, let us take the same example of price data from July 22 to July 31 2020. We have added the percentage returns and cumulative returns as shown below.
|
Date |
Closing Price |
Percentage returns |
Cumulative Returns |
|
22-07-2020 |
97.2 |
||
|
23-07-2020 |
92.8 |
-4.53% |
0.95 |
|
24-07-2020 |
92.6 |
-0.22% |
0.95 |
|
27-07-2020 |
94.8 |
2.38% |
0.98 |
|
28-07-2020 |
93.3 |
-1.58% |
0.96 |
|
29-07-2020 |
95 |
1.82% |
0.98 |
|
30-07-2020 |
96.2 |
1.26% |
0.99 |
|
31-07-2020 |
106.3 |
10.50% |
1.09 |
You have bought one stock of Apple a few days back and you have no more capital left. The only two choices for you are “hold” or “sell”. As a first step, you need to create a simple reward table.
If we decide to hold, then we will get no reward till 31 July and at the end, we get a reward of 1.09. And if we decide to sell on any day then the reward will be cumulative returns up to that day. The reward table (R-table) looks like below. If we let the RL model choose from the reward table, the RL model will sell the stock and gets a reward of 0.95.
|
State/Action |
Sell |
Hold |
|
22-07-2020 |
0 |
0 |
|
23-07-2020 |
0.95 |
0 |
|
24-07-2020 |
0.95 |
0 |
|
27-07-2020 |
0.98 |
0 |
|
28-07-2020 |
0.96 |
0 |
|
29-07-2020 |
0.98 |
0 |
|
30-07-2020 |
0.99 |
0 |
|
31-07-2020 |
1.09 |
1.09 |
But the price is expected to increase to $106 on July 31 resulting in a gain of 9%. Therefore, you should hold on to the stock till then. We have to represent this information. So that the RL agent can make better decisions to Hold rather than Sell.
How to go about it? To help us with this, we need to create a Q table. You can start by copying the reward table into the Q table and then calculate the implied reward using the Bellman equation on each day for Hold action.
Bellman Equation
$$ Q(s_t,a_t^i) = R(s_t,a_t^i) + \gamma Max[Q(s_{t+1},a_{t+1})] $$In this equation, s is the state, a is a set of actions at time t and ai is a specific action from the set. R is the reward table. Q is the state action table but it is constantly updated as we learn more about our system by experience. γ is the learning rate
We will first start with the q-value for the Hold action on July 30.
- The first part is the reward for taking that action. As seen in the R-table it is 0
- Let us assume that γ = 0.98. The maximum Q-value for sell and hold actions on the next day, i.e. 31 July, is 1.09
- Thus q-value for Hold action on 30 July is 0 + 0.98 (1.09) = 1.06
In this way, we will fill the values for the other rows of the Hold column to complete the Q table.
|
Date |
Sell |
Hold |
|
23-07-2020 |
0.95 |
0.966 |
|
24-07-2020 |
0.95 |
0.985 |
|
27-07-2020 |
0.98 |
1.005 |
|
28-07-2020 |
0.96 |
1.026 |
|
29-07-2020 |
0.98 |
1.047 |
|
30-07-2020 |
0.99 |
1.068 |
|
31-07-2020 |
1.09 |
1.090 |
The RL model will now select the hold action to maximise the Q value. This was the intuition behind the Q table. This process of updating the Q table is called Q learning. Of course, we had taken a scenario with limited actions and states. In reality, we have a large state space and thus, building a q-table will be time-consuming as well as a resource constraint.
To overcome this problem, you can use deep neural networks. They are also called Deep Q networks or DQN. The deep Q networks learn the Q table from past experiences and when given state as input, they can provide the Q-value for each of the actions. We can select the action to take with the maximum Q value. Learn how neural network in trading can enhance your skills with an advanced course.
How to train artificial neural networks?
We will use the concept of experience replay. You can store the past experiences of the agent in a replay buffer or replay memory. In layman language, this will store the state, action taken and reward received from it. And use this combination to train the neural network.
Key Challenges
There are mainly two issues which you have to consider while building the RL model. They are as follows:
Type 2 Chaos
This might feel like a science fiction concept but it is very real. While we are training the RL model, we are working in isolation. Here, the RL model is not interacting with the market. But once it is deployed, we don’t know how it will affect the market.
Type 2 chaos is essentially when the observer of a situation has the ability to influence the situation. This effect is difficult to quantify while training the RL model itself. However, it can be reasonably assumed that the RL model is still learning even when it is deployed and thus will be able to correct itself accordingly.
Noise in Financial Data
There are situations where the RL model could pick up random noise which is usually present in financial data and consider it as input which should be acted upon. This could lead to inaccurate trading signals.
While there are ways to remove noise, we have to be careful of the tradeoff between removing noise and losing important data.
While these issues are definitely not something to be ignored, there are various solutions available to reduce them and create a better RL model in trading.
Conclusion
We have only touched the surface of reinforcement learning with the introduction of the components which make up the reinforcement learning system. The next step would be to take this learning forward by implementing your own RL system to backtest and paper trade on real-world market data.
You can enroll for the course on Deep reinforcement learning trading to learn the RL model in detail and also create your own Reinforcement learning trading strategies.
Check it out here.
References & Further Readings
- Reinforcement Learning in Financial Markets - A Survey
- Key Papers in Deep RL
- Deep RL from DeepMind Technologies
- RL for Optimized Trade Execution
- Enhancing Q-Learning for Optimal Asset Allocation
- Reinforcement Learning for Trading Systems and Portfolios
Industry Updates
- AI and Machine Learning Gain Momentum with Algo Trading & ATS Amid Volatility
- RBC Capital Markets launches Aiden, an AI-powered electronic trading platform
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.

