
By Mario Pisa
As analysts, we spend a lot of time processing, transforming and inferring data, we handle large amounts of data and devote a great deal of time to its analysis and manipulation.
It is convenient to have a mechanism that allows us to save the processed data for future retrieval without going through the same costly process again. Pickle is a utility that allows us to save Python objects in a binary file. In other words:
Pickle allows us to save time.
Here, we cover:
- The need for Pickle Python
- What is Pickle Python?
- Example of Pickle Python
- How to use Pickle Python to save work
- How to use Pickle Python to retrieve work
The need for Pickle Python
When we process large amounts of data in our analysis and backtesting, the machine needs a few hours, if not days, to process all the information.
The backtesting of a large portfolio of financial assets with historical data running into decades or the training of our ML algorithms are heavy processes from the point of view of the machine time needed to digest the data.
Repeating this procedure over and over again, most of the time, is pointless and a waste of time and resources. So it is convenient to have a mechanism that allows us to save the processed data for future retrieval without having to repeat the same costly process.
In Python there are multiple mechanisms and formats such as plain text files, binary files and structured and unstructured databases.
Among the most popular plain text files are csv (comma separated values), json (JavaScript Object Notation) or xml (eXtended Markup Language). The main feature of plain text files is that they are human-readable and can be exchanged between machines.
Structured and unstructured databases are able to store large amounts of information, relate data to each other and provide fast and accurate answers to queries.
Finally, we can use binary files to store the information. These files are not human-readable since they store bytes of information that can only be understood by machines.
Their main characteristic is the speed of storage/retrieval and the small size compared to the previous ones. Pickle is a utility that allows us to save Python objects in a binary file.
What is Pickle Python?
From the official documentation, the technical explanation about Pickle Python is as follows:
The pickle module implements binary protocols for serializing and de-serializing a Python object structure.
“Pickling” is the process whereby a Python object hierarchy is converted into a byte stream, and “unpickling” is the inverse operation, whereby a byte stream (from a binary file or bytes-like object) is converted back into an object hierarchy.
Pickling (and unpickling) is alternatively known as “serialization”, “marshalling,” 1 or “flattening”; however, to avoid confusion, the terms used here are “pickling” and “unpickling”.
For simplicity, we can say that Pickle stores and retrieves Python objects to/from the machine's RAM.
It is important to remember here that in Python even variables are objects and that regardless of where the data we are handling comes from, the information resides in the machine's volatile memory, also called RAM (Random Access Memory).
Unless we save this information in a storage system such as a hard disk, in any file format kind or database, the information is lost at the end of the Python session.
Example of Pickle Python
Let’s suppose the following scenarios.
Pickle Python Scenario 1

The figure shows a very high level abstraction typically seen in a ML project.
The ETL (Extraction, Transformation and Load) is the tool for:
- Extract or fetch data from the data source,
- Transform the data by cleaning, sanitizing, checking, resumes, inferences, relations, etc. and finally
- Load in a database, save csv/hdf5 files or load into the model directly.
The Model Training is the most cumbersome process from the point of view of CPU time, it is also a very cumbersome process from the analyst's point of view as the model requires adjustments until it is trained.
Once the model has been trained and adjusted, it is necessary to test the model's performance and verify if it fits the training provided.
Ideally, after a lot of work and effort, we should obtain a model that allows us to make forecasts about something.
The problem here is that if we turn off the machine, we have to repeat the whole process. Maybe with luck, we have saved the data after the ETL process, but we must in any case perform the training and testing.
In a simple prototype, this may not be a problem, but when we have trained a model that has needed hours, if not days of work, a tool like Pickle Python allows us to save huge amounts of work and, therefore, time.
Pickle Python Scenario 2
In the following scenario, we can see a Pickle object between the testing process and the forecasting process.
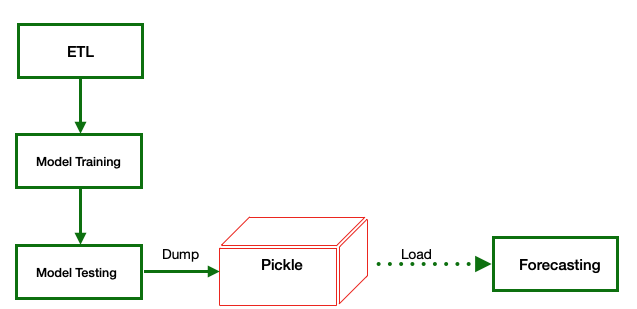
In short, Pickle allows us to dump the Python objects in memory to a binary file to retrieve them later and continue working. Let's see how to dump the memory to the file and load the memory from the file later.
How to use Pickle Python to save work
The process of dumping objects from RAM to binary file with Pickle Python is quite simple:
import pickle
pickle.dump(object, model_x.pkl, other_params)
This simple line of code certainly saves us a great deal of work. On the other hand, the function accepts many other parameters for which it is recommended to consult the official documentation.
How to use Pickle Python to retrieve work
The loading process from binary Pickle file to RAM is just as simple:
import pickle
model = pickle.load(model_x.pkl)
With this simple line of code we get our model back in memory as if we had just finished the model testing process.
It is important to note that loading unknown Pickle files into RAM can seriously compromise the security of the machine, so it is not recommended to use pickle files of unknown origin.
Conclusion
Pickle is a fantastic tool for dumping Python objects that are necessarily in memory as long as the Python session lasts.
When the Python session ends, the contents of memory are lost and generally all the information has to be reprocessed. With Pickle we can dump the RAM to a binary file, to recover the memory content in another Python session avoiding reprocessing all the information.
If you consider machine learning as an important part of the future in financial markets, you can't afford to miss this highly-recommended track for those interested in Machine Learning and its applications in trading by Quantra - Learning Track: Machine Learning & Deep Learning in Financial Markets. Enroll now!
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.
