
By Chainika Thakar & Shagufta Tahsildar
In the realm of algo trading, the random forest algorithm offers a powerful approach for enhancing trading strategies.
In today's data-driven landscape, the utilization of machine learning algorithms has expanded across diverse domains. Each algorithm has its own unique characteristics and functions, catering to different problem domains. Random forest algorithms is a prime example of an algorithm developed to address the limitations encountered with decision trees. As Machine learning algorithms continue to evolve and improve, their application scope widens, allowing for enhanced problem-solving capabilities.
This blog covers:
- What are decision trees and its limitation?
- What is a random forest?
- Working of random forest algorithm in machine learning
- Steps to use random forest algorithm for trading in Python
- Pros of using random forest algorithm
- Cons of using random forest algorithm
What are decision trees and its limitation?
Decision trees, characterized by their hierarchical structure, use nodes and branches to guide decision-making based on parameter responses.
However, they are prone to overfitting as they become overly complex and specific.
In both machine learning, overfitting occurs when the model fits the data too well. Overfitting model learns the detail and noise in the training data to such an extent that it negatively impacts the performance of the model on new data/test data.
You can learn more about decision trees with this Free Preview of the course Decision trees in trading.
What is a random forest?
Random forest algorithm in machine learning is a supervised classification algorithm that addresses the issue of overfitting in decision trees through an ensemble approach. It consists of multiple decision trees constructed randomly by selecting features from the dataset.
The final prediction of the random forest is determined by aggregating the outcomes from the decision trees, with the most frequent prediction.
The outcome which is arrived at, for a maximum number of times through the numerous decision trees is considered as the final outcome by the random forest.
Working of random forest algorithm in machine learning
Random forests utilise ensemble learning techniques by combining multiple decision trees. The accuracy of ensemble models exceeds that of individual models by aggregating their results to produce a final outcome.
To select features for decision tree construction in the Random Forest, a method called bootstrap aggregating or bagging is employed. Random subsets of features are created by selecting features randomly with replacement. This random selection allows for variability and reduces correlation among the trees, effectively addressing the issue of overfitting.
Each tree is constructed based on the best split determined by the selected features, typically evaluated using the decision tree Gini impurity to find the feature and threshold that best separates the classes. The output of each tree represents a "vote" towards a specific outcome. The Random Forest considers the output with the highest number of votes as the final result or, in the case of continuous variables, averages the outputs to determine the final outcome.
For example, in the diagram below, we can see that there are two trading signals:
- 1 - is the buy signal
- 0 - is the sell signal
We can observe that each decision tree has voted or predicted a specific trading signal. The final output or signal selected by the Random Forest will be 1, as it has majority votes or is the predicted output by two out of the three decision trees.

Also, this way, random forest algorithm helps avoid overfitting in the decision trees.
You can learn it in more detail in the free preview (Section 13, Unit 1) of our course titled Machine Learning for Options Trading.
Steps to use random forest algorithm for trading in Python
In general, the steps to use random forest in trading are:
Data Preparation
Collect and preprocess historical market data, perform cleaning, normalization, and feature engineering to enhance the dataset's quality and relevance.
Data Split
Split the dataset into training and testing sets to evaluate the Random Forest model's performance accurately
Building and Training the Model
Utilize Python's scikit-learn library to implement the Random Forest algorithm, fine-tune hyperparameters, and train the model using the training dataset.
Feature Importance and Interpretability
Extract valuable insights by interpreting the Random Forest model's feature importance rankings. Understand the influential factors driving trading strategies.
Backtesting and Strategy Evaluation
Apply the trained Random Forest model to historical market data for backtesting and evaluate the performance of the trading strategy using relevant metrics.
Now, let us check the steps in the python code, which are as follows:
Step 1 - Import libraries
In this code, we will be creating a Random Forest Classifier and train it to give the daily returns.
The libraries imported above will be used as follows:
- yfinance - this will be used to fetch the price data of the BAC stock from yahoo finance.
- numpy - to perform the data manipulation on BAC stock price to compute the input features and output. If you want to read more about numpy then it can be found here.
- sklearn - Sklearn has a lot of tools and implementation of machine learning models. RandomForestClassifier will be used to create Random Forest classifier model.
Step 2 - Fetching the data
The next step is to import the price data of stock from yfinance. We will use IBM for illustration.
Output:
[*********************100%***********************] 1 of 1 completed
|
Open |
High |
Low |
Close |
Adj Close |
Volume |
|
|
Date |
||||||
|
2023-06-23 |
130.399994 |
130.619995 |
129.179993 |
129.429993 |
129.429993 |
11324700 |
|
2023-06-26 |
129.389999 |
131.410004 |
129.309998 |
131.339996 |
131.339996 |
4845600 |
|
2023-06-27 |
131.300003 |
132.949997 |
130.830002 |
132.339996 |
132.339996 |
3219900 |
|
2023-06-28 |
132.059998 |
132.169998 |
130.910004 |
131.759995 |
131.759995 |
2753800 |
|
2023-06-29 |
131.750000 |
134.350006 |
131.690002 |
134.059998 |
134.059998 |
3639800 |
Step 3 - Creating input and output dataset
In this step, we will create the input and output variable.
- Input variable: We have used '(Open - Close)/Open', '(High - Low)/Low', standard deviation of last 5 days returns (std_5), and average of last 5 days returns (ret_5)
- Output variable: If tomorrow’s close price is greater than today's close price then the output variable is set to 1 and otherwise set to -1. 1 indicates to buy the stock and -1 indicates to sell the stock.
The choice of these features as input and output is completely random.
Step 4 - Train Test Split
We now split the dataset into 75% Training dataset and 25% for Testing dataset.
Output:
844
Output:
(844, 4) (282, 4) (844,) (282,)
Step 5 - Training the machine learning model
All set with the data! Let's train a decision tree classifier model. The RandomForestClassifier function from the tree is stored in variable ‘clf’ and then a fit method is called on it with ‘X_train’ and ‘y_train’ dataset as the parameters so that the classifier model can learn the relationship between input and output.
Output:
Correct Prediction (%): 50.70921985815603

Step 6 - Strategy returns
Now, we will visualize the strategy returns in the histogram plot.
Output:
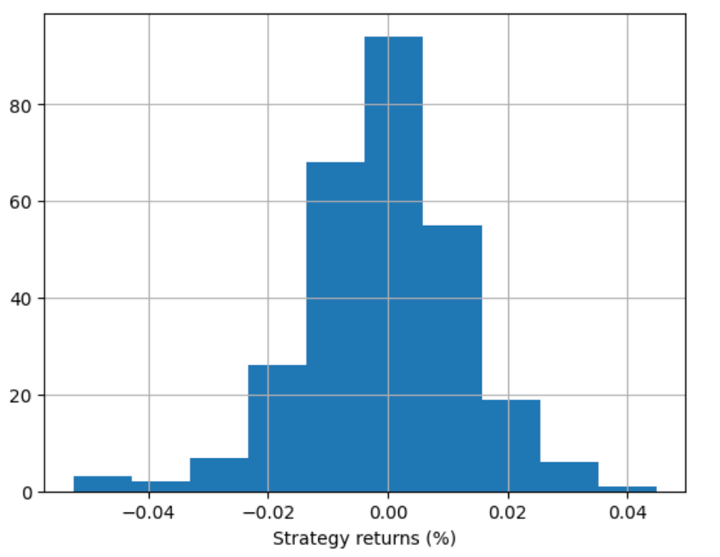
You can show the strategy returns as a line chart also.
Output:

The output displays the strategy returns according to the code for the Random Forest Classifier.
Pros of using random forest algorithm
Here are some pros of using random forest algorithm:
- Robustness: Random Forest is known for its robustness against overfitting, as it combines multiple decision trees and reduces the risk of individual trees making erroneous predictions.
- Accuracy: Random Forest tends to provide high accuracy in both classification and regression tasks, as it aggregates predictions from multiple trees and reduces the impact of outliers or noisy data.
- Feature Importance: Random Forest provides a measure of feature importance, allowing users to identify the most influential features in the dataset. This can aid in feature selection and provide insights into the underlying relationships.
- Handling Large Datasets: Random Forest can handle large datasets with high dimensionality, making it suitable for analysing complex financial data that often contains numerous features.
Cons of using random forest algorithm
Let us now see some cons of using random forest algorithm below:
- Computational Complexity: Training a Random Forest with a large number of trees and features can be computationally expensive, requiring more resources and time compared to simpler algorithms.
- Hyperparameter Tuning: Random Forest has several hyperparameters that need to be tuned for optimal performance. Finding the right combination of hyperparameters can be time-consuming and may require extensive experimentation.
- Interpretability: While Random Forest provides feature importance, the overall model can be challenging to interpret due to the complexity and interaction of multiple decision trees.
- Biased Predictions: If the dataset contains imbalanced classes, Random Forest may be biased towards the majority class, leading to skewed predictions and lower accuracy for minority classes.
It's important to consider these advantages and disadvantages while applying the Random Forest algorithm in the trading domain. The specific characteristics of the dataset and the desired outcomes should be carefully evaluated to determine whether Random Forest is an appropriate choice.
Bibliography
- How to Develop a Random Forest Ensemble in Python
- Random Forest in Python
- Definitive Guide to the Random Forest Algorithm with Python and Scikit-Learn
Conclusion
The random forest algorithm offers advantages such as robustness, high accuracy, and the ability to handle large and complex datasets in algorithmic trading. However, it requires computational resources and hyperparameter tuning, and its interpretability can be challenging.
Additionally, it may exhibit biased predictions in imbalanced datasets. Overall, when applied judiciously, random forest can enhance trading strategies and provide valuable insights in the dynamic domain of algorithmic trading.
If you wish to learn more about random forest algorithms in trading using python, you must check out our course on Decision Trees in Trading. This course is offered by Dr. Ernest Chan. You will learn to predict markets and find trading opportunities using machine learning techniques. Moreover, with this course you can learn to train the algorithm to go through hundreds of technical indicators (You can learn all about in this course on technical indicators python.) to decide which indicator performs best in predicting the correct market trend. Further, you can optimize these AI models and learn how to use them in live trading.
The use of AI in trading has become essential for identifying trends and creating predictive strategies. AI-driven techniques allow traders to leverage large datasets for quick, data-driven decisions, transforming market analysis and trading efficiency.
To improve your Random Forest model, consider integrating Yahoo Finance Futures data. This addition can provide valuable market insights, enhancing prediction accuracy and robustness. By expanding your dataset to include futures, you can develop a more informed and comprehensive trading strategy. For further guidance, explore how to incorporate Yahoo Finance Futures data into your trading models.
Note: The original post has been revamped on 31st July 2023 for accuracy, and recentness.
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.
