
Compiled by: Chainika Thakar
In recent years, large language models (LLMs) like GPT-4 have revolutionised various industries, including finance. These powerful models, capable of processing vast amounts of unstructured text, are increasingly being used by professional traders to gain insights into market sentiment, develop trading strategies, and automate complex financial tasks.
You must be aware of how sentiment analysis is being done by traders with the help of news, but if you wish to learn more about the same, you can enrol into this course with the link here.
In this blog, you will explore how LLMs are integrated into trading workflows, using tools like FinBERT, Whisper, and more to enhance decision-making and performance.
Please note that we have prepared the content in this article almost entirely from a QuantInsti course by Dr. Hamlet Medina and Dr. Ernest Chan.
About the speakers
Dr Ernest Chan is the CEO of Predictnow.ai and Dr Hamlet Medina is the Chief Data Scientist, Criteo and in the webinar, they discuss how LLMs can help us analyse the sentiment of event transcripts.
You can watch the webinar below for a detailed exploration of the topic. This webinar is a piece of advanced information meant for individuals already in the trading domain using technology.
Here is what this blog covers:
- What is an LLM or a Generative AI?
- How can LLMs be improved?
- What are financial LLMs?
- The role of sentiment analysis in trading using LLMs
- Sentiment analysis trading process
- Sentiment analysis of FOMC transcripts
- Real-world applications
- LLM models that help with sentiment analysis
- How to understand sentiment scores?
- FAQs
What is an LLM or a Generative AI?
A Large Language Model (LLM) is a generative AI that understands and generates human-like text. Models like OpenAI's GPT or Google's BERT are trained on massive amounts of data, such as books, articles, and websites. These models are built using billions of parameters, which help them perform tasks like answering questions, summarising information, translating languages, and analysing sentiment.
They are called generative AIs because unlike traditional AI, which typically focuses on recognising patterns or making decisions based on existing data, generative AI can produce original outputs by predicting what comes next in a sequence.
Because of their flexibility, LLMs are used in many fields, including finance, healthcare, law, and customer service. In finance, for example, LLMs can analyse news, reports, or social media to provide insights for market predictions, risk management, and strategy development.
For instance, given the sentence, “Due to the pandemic declaration, the S&P 500,” an LLM might predict "declined" as the next word based on the previous words.
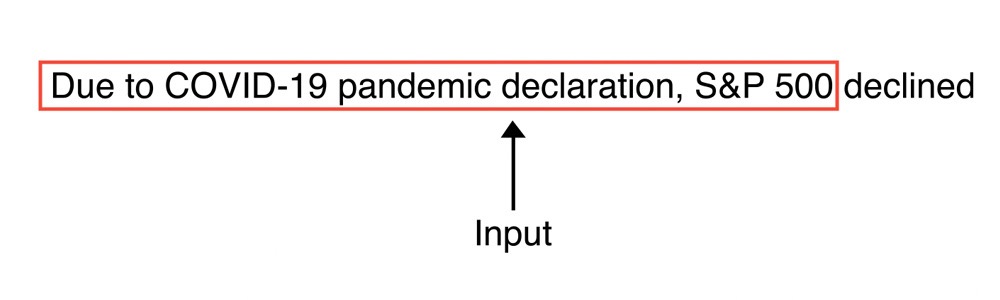
Figure: Prediction by LLMs
How are LLMs able to predict the next word?
You can use any data you have access to for training the LLM model. In fact, you can use the entire internet to train the LLM. Once you have given the input, the LLM will give you an output. Further, it will check the predicted output with the actual output variable and based on the error, it will adjust its prediction accordingly. This process, called pre-training, is the foundation of how LLMs understand language.
This was about the introduction of LLMs, but if you wish to learn more about the particular LLM model known as “ChatGPT” and how it can help with trading, you must read this blog here.
This blog covers almost everything that you need to know about trading with ChatGPT including the steps of implementation using prompts. Also, the blog will take you through ChatGPT’s machine learning usage, strategies, the future and so much more!
Further, we will continue the discussion about LLMs and then find out how they can be improved to maximise their use.
How can LLMs be improved?
After pre-training, LLMs are often further enhanced through techniques like Reinforcement Learning through Human Feedback (RLHF) conducted by specialised teams within organisations (such as ChatGPT and OpenAI) that develop LLMs. In RLHF, human reviewers rank multiple outputs generated by the LLM.
For example, for a given sentence, outputs like "declined," "exploded," or "jumped" might be produced, with "declined" being ranked the highest by human reviewers as shown in the image below.
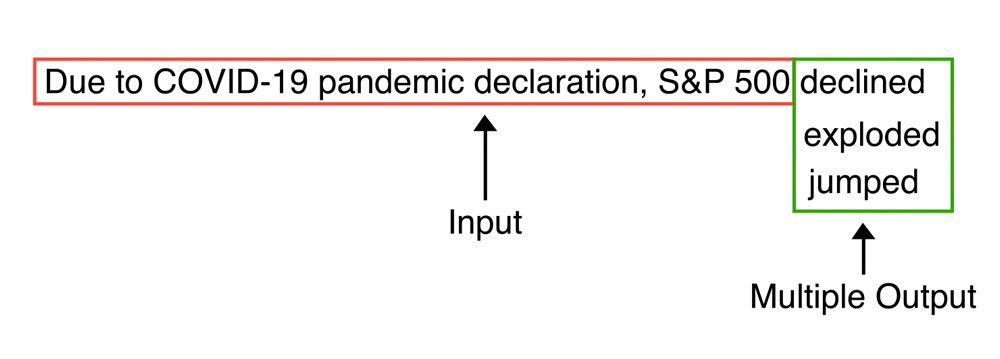
Figure: Multiple Output Prediction by LLMs
The model then learns from these rankings, improving its predictions for future tasks.
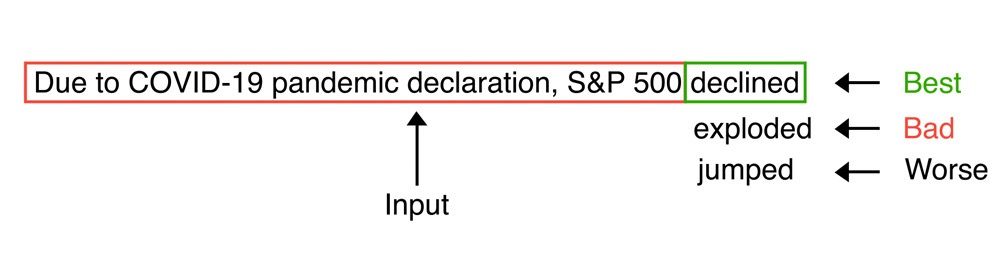
Figure: Ranking of LLM Output by Human Reviewers
Further, let us discuss the meaning of financial LLMs and their use in trading.
What are financial LLMs?
While general-purpose LLMs are helpful, models trained on specific data types perform even better for niche tasks. This is where financial LLMs come in. Models like BloombergGPT and FinBERT have been fine-tuned on financial datasets, allowing them to better understand and predict outcomes within the financial sector.
For instance, FinBERT is trained on top of the BERT model using datasets from financial news articles and financial phrase banks, enabling it to capture the nuances of finance-specific language.
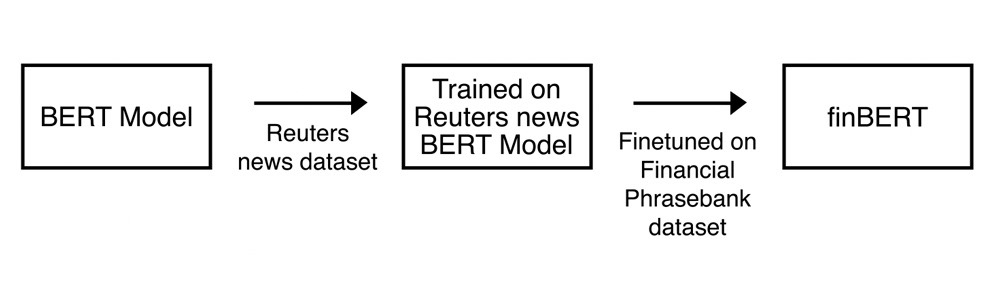
Figure: Training of FinBERT
Next, let us check out the role of sentiment analysis in trading using LLMs.
The role of sentiment analysis in trading using LLMs
Dr. Hamlet Medina explains how one of the alternative data techniques, that is, sentiment analysis plays a critical role in finance by converting qualitative data, such as news articles, speeches, and reports, into quantitative insights that can influence trading strategies.
By leveraging advanced natural language processing (NLP) models like ChatGPT, financial institutions can systematically assess the sentiment behind news reports or statements from influential figures, such as central bank officials, and use this information to make informed market decisions.
Sentiment analysis in this context involves determining whether the tone of a news article or speech is positive, negative, or neutral. This sentiment can reflect market conditions, investor confidence, or potential economic shifts. Dr. Medina highlights that models like ChatGPT are trained on vast datasets, allowing them to recognise patterns in language and sentiment across different sources. These models then evaluate the emotional and factual content of texts, extracting insights about market direction or volatility.
For example, if a central bank statement suggests a cautious economic outlook, sentiment analysis could flag this as a potential signal for market downturns, prompting traders to adjust their positions accordingly. By translating complex linguistic data into actionable insights, sentiment analysis tools have become essential for predictive modelling and risk management in modern finance.
Further, to develop your career in modern methods in finance, there is this course that covers various aspects of trading, investment decisions & applications using News Analytics, Sentiment Analysis and Alternative Data. This course is titled Certificate in Sentiment Analysis and Alternative Data for Finance (CSAF) and you can access it here.
Let us now see what is meant by the sentiment analysis trading process.
Sentiment analysis trading process
The sentiment analysis trading process involves a series of steps that transform raw financial text data into actionable trading insights. Here’s a streamlined approach that traders can follow:
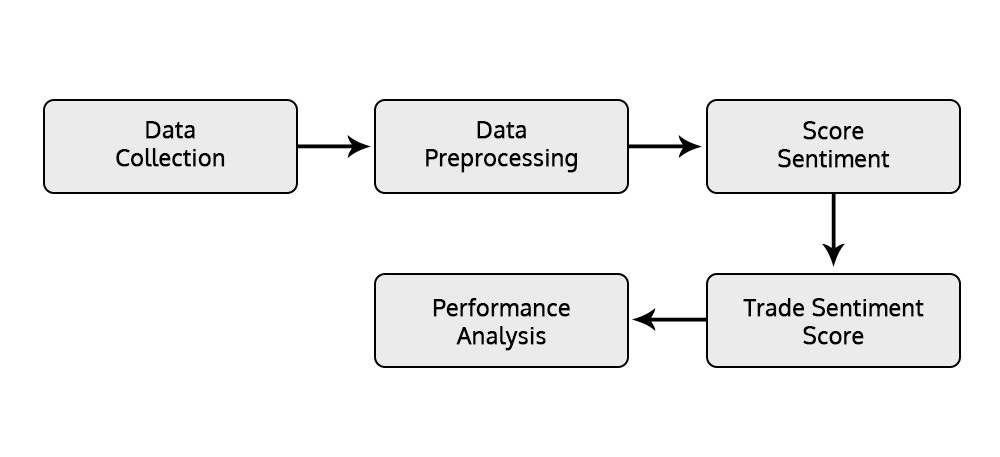
Figure: Sentiment Analysis Trading Process
- Data Collection: Gather raw data from sources like FOMC transcripts or earnings calls. This can be in text, audio, or video form from official websites.
- Data Preprocessing: Clean the data by transcribing, removing irrelevant content, and segmenting it to ensure it's ready for analysis.
- Sentiment Scoring: Use models like FinBERT to assign sentiment scores (positive, negative, or neutral) to the processed data.
- Trading Strategy: Apply these sentiment scores to your strategy by setting thresholds to trigger trades based on market sentiment shifts during key events.
- Performance Analysis: Evaluate both strategy and trade-level performance to study profitability.
This process allows traders to effectively incorporate sentiment analysis into their trading strategies for better decision-making.
Let’s understand how this sentiment analysis trading process is applied to analyse the FOMC transcripts and trade as per the sentiment.
Sentiment analysis of FOMC transcripts
FOMC transcripts refer to the financial records of the Federal Open Market Committee meetings. FOMC transcripts provide key insights into monetary policy, economic assessments, and future outlooks, shaping U.S. monetary policy and hence, the market sentiment and trading strategies.
The analysis begins with data collection from the Federal Reserve’s official website. The transcripts are then preprocessed to remove irrelevant sections and focus on content that reflects market sentiment. FinBERT is used to assign sentiment scores, helping traders gauge whether the sentiment is positive or negative.
The following table represents sentiment scores of FOMC transcripts at a minute frequency. Each row corresponds to a specific minute during the transcript. For example, the meeting text from 19:30 to 19:31 is stored in the ‘text’ column and the sentiment score of this text, which is 0.395, is stored in the column ‘sentiment_score’.
This analysis helps quantify how the sentiment changes over time during the FOMC meeting.

Figure: Table with FOMC transcripts text at minute frequency and its sentiment score
Next, we will discuss the trading strategy based on sentiment analysis.
Trading strategy based on sentiment analysis
The strategy revolves around analysing rolling sentiment scores and establishing specific thresholds for trading decisions.
Generating Trade Signals: The first step involves calculating the rolling mean of sentiment scores, which reflects the average sentiment over the minute-wide data collected throughout the FED meeting. By averaging these scores, traders can gauge the prevailing market sentiment and make informed trading decisions based on the trends observed.
You can find the rolling sentiment score in the ‘rolling_sentiment_score’ column in the following table. It should be noted that the sentiment score values are rounded off to two decimals.

Figure: Table with FOMC transcripts text with their sentiment score and rolling sentiment score
For example, the rolling sentiment score at 19:30:00 (0.14) is an average of sentiment scores so far, which is an average of 0.4 and -0.12.
Similarly, the rolling sentiment score at 19:32:00 (0.08) is an average of 3 sentiment scores 0.4, -0.12, -0.05.
Setting Thresholds: In this strategy, a sentiment score greater than 0 indicates positive sentiment, while a score below 0 suggests negative sentiment. In this example, a threshold of 0.1 will be used.
Entry and Exit Rules:
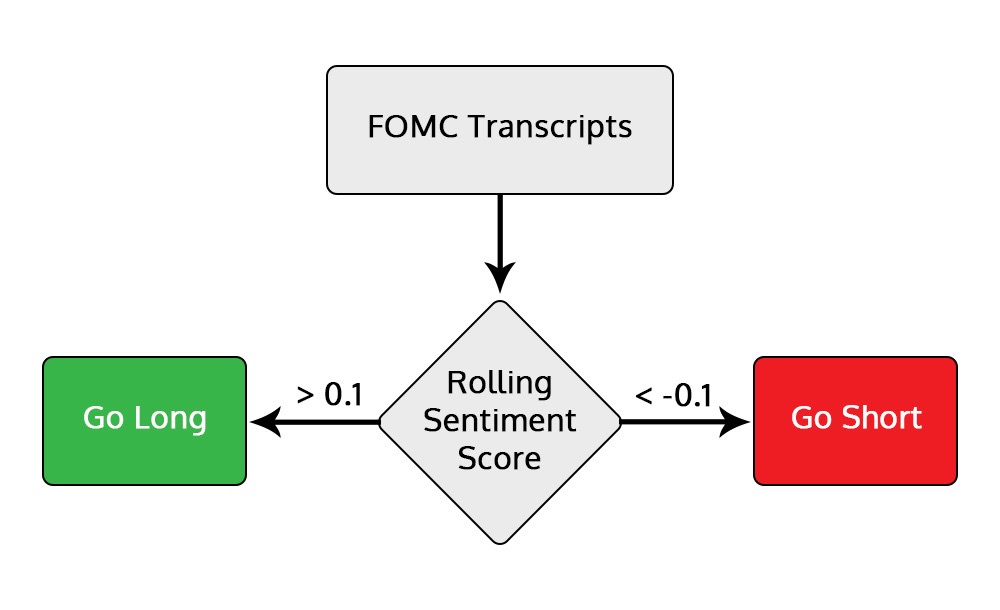
Figure: Entry rules of long and short position
Long Position: Enter when the rolling sentiment score is greater than 0.1. Exit the position either when the rolling sentiment falls below -0.1 or at the last minute of the FOMC meeting.
Short Position: Open a short position when the rolling sentiment score is less than -0.1. Exit when the rolling sentiment exceeds 0.1 or at the last minute of the FOMC meeting.
Let us now check out the real-world application of using some news or information and performing sentiment analysis on the same.
Real-world applications
Below is the example with the screenshot taken from the press release video in which a press conference and the SPY price movements right next to it during the conference are shown. You can see how Federal announcements influence your trading strategy and how AI can help you make the right decisions in real-time.
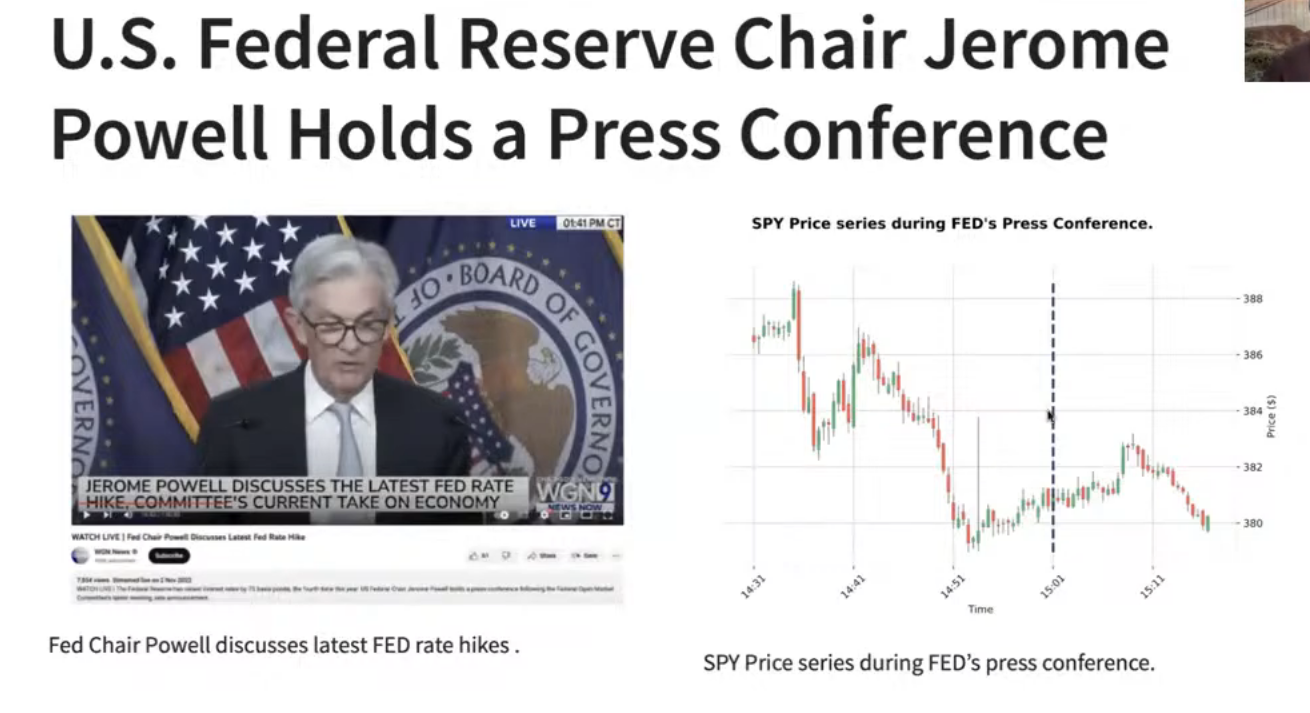
This video can be converted into sentiment by using the following approach.
For every 30-second trading bar of SPY data, we would -
- Extract audio from the video up to that particular bar of SPY.
- Perform speech-to-text conversion.
- Perform sentiment analysis based on text.
- Generate signals to make buy and sell decisions.
Since we know how well LLMs handle text, we will use the LLM model only for the above analysis and signal generation.
You can see below how text and sentiment scores would appear on each 30-second timestamp.
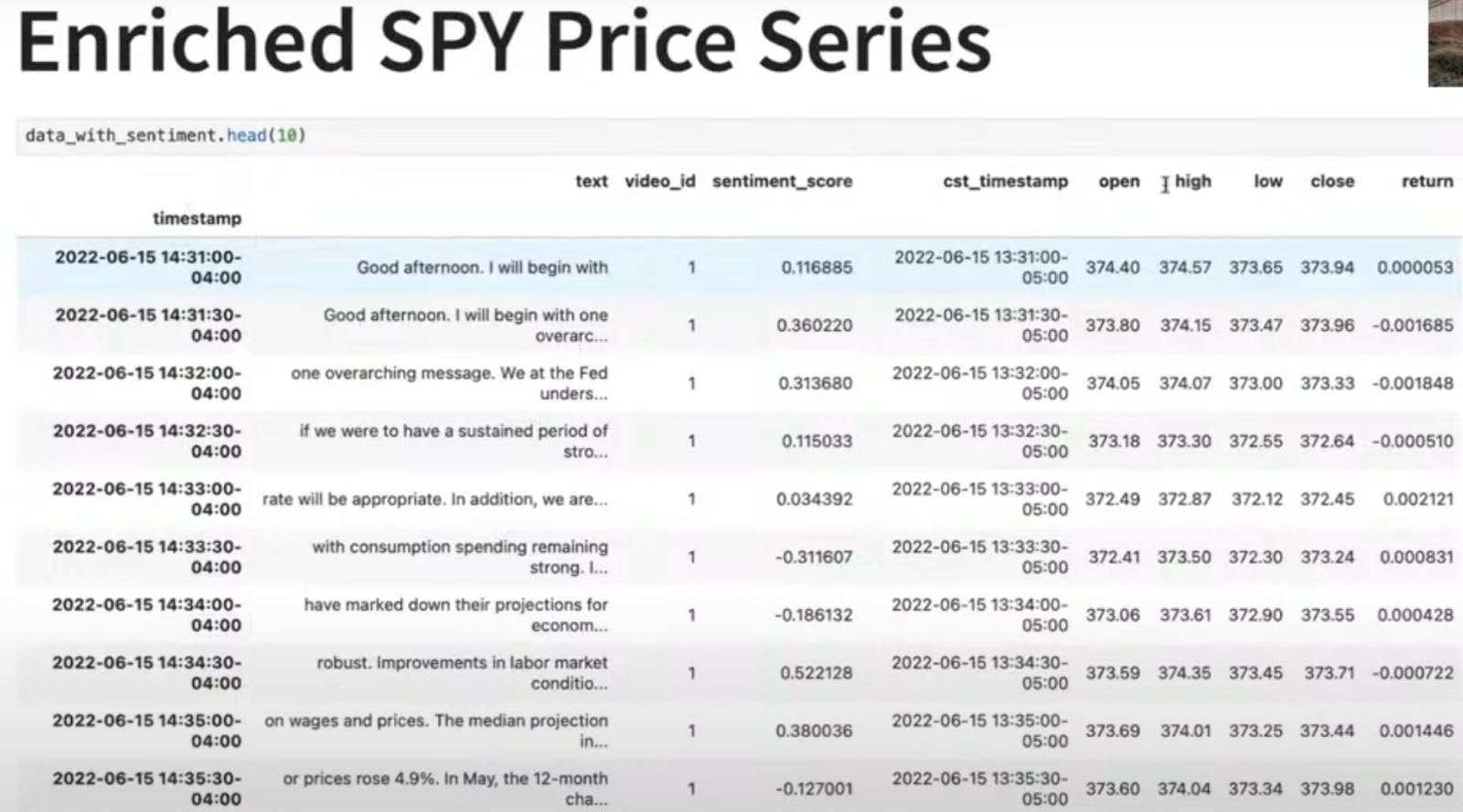
So, here is the summary of the working below.

But once you have the sentiment scores, how to understand the same? Let us discuss the understanding of sentiment scores next.
How to understand sentiment scores?

Figure: Range of finBERT Sentiment Score
Sentiment scores produced by FinBERT range from -1 to +1:
- Scores closer to +1 represent highly positive sentiment.
- Scores closer to -1 indicate strongly negative sentiment.
For example, a score of 0.1 shows a slightly positive sentiment, reflecting the mildly optimistic tone of the earnings report.
When analysing FOMC transcripts, the text is passed through FinBERT to generate sentiment scores for various sections of the meeting. This gives traders a clear picture of market sentiment during the FOMC meeting, helping them to make informed decisions based on real-time data.
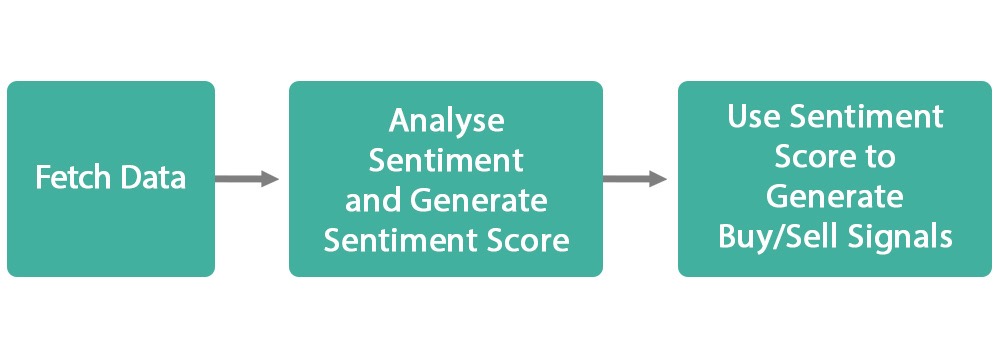
Figure: Steps to Generate Trading Signals Using LLMs
In the image below, we have fetched the FOMC Meeting transcripts and analysed the sentiment of the speech at 1-minute intervals.

Figure: Analysing Sentiment Score Using LLM
For example, at the end of the first minute, the finBERT model gave a sentiment score of 0.3. You can create an entry rule that if the sentiment score is above a threshold of 0.1, you will generate a buy signal.
We will now check out those generative AI tools, or to put it more simply, the LLM models which are highly preferred for sentiment analysis.
LLM models that help with sentiment analysis
Dr. Hamlet Medina introduces two LLM models and one of them is a neural network called “Whisper”, designed for highly accurate and robust English speech recognition, approaching human-level performance.
Whisper is an open-source model, freely available for download and use on any computer. Its primary feature is the ability to directly convert audio into text, making it a powerful tool for tasks like sentiment analysis. By transcribing spoken content, such as news reports, interviews, or speeches, into text, Whisper allows financial analysts to process and analyse large amounts of speech data, extracting valuable insights for decision-making in areas like market sentiment or economic trends.
Another one is an NLP model called “FinBERT”, it's essential to understand how they specialise in providing sentiment scores specifically for financial texts, which sets them apart from more general-purpose models. FinBERT is fine-tuned on financial data, making it highly accurate in analysing sentiment in news articles, earnings reports, and other finance-related content.
If you are wondering how FinBERT is different from GPT or BERT, then here are the reasons-
- It excels at identifying positive, negative, or neutral sentiment in a way that is more relevant to financial markets compared to general NLP models like GPT or BERT, which may not grasp the nuances of financial terminology as effectively.
- Compared to other models, FinBERT’s advantage lies in its domain-specific training. It handles financial jargon, understands market-specific sentiment, and offers more precise sentiment analysis in contexts like stock performance predictions or risk analysis. General-purpose models might miss these nuances or misinterpret complex financial language.
- In practical applications, FinBERT is often used with Python for sentiment analysis tasks. Python libraries like Hugging Face make it easy to load and implement FinBERT for scoring sentiment in financial texts. Additionally, combining FinBERT with a speech recognition model like Whisper creates a powerful workflow. Whisper converts audio (like news broadcasts or earnings calls) into text, and then FinBERT analyses the sentiment of that text. This synergy allows financial analysts to process both written and spoken data efficiently, turning audio sources into actionable insights.
If you would like to learn Python, you can check out two courses out of which, one is FREE. Click on the link to access the free Python course. Next is the advanced version of the same, which can be accessed via this link.
FinBERT and its use for sentiment analysis
Let's consider a sentence like: "Shares of food delivery companies surged despite the catastrophic impact of the coronavirus on global markets." A trader would focus on the first part, recognising a positive sentiment around food delivery companies, while a general model might give more weight to the negative sentiment in the latter half.

Figure: Sentiment Analysis Example
FinBERT, being trained on financial data, would understand the trader’s context and provide a more accurate sentiment score. The sentiment score tells us whether the overall sentiment of the text is positive, neutral, or negative. By doing so, it helps traders identify opportunities in the market more precisely.
FinBERT is an essential tool for traders looking to analyse sentiment from financial texts such as FOMC meeting transcripts.
How Do You Use FinBERT To Generate A Sentiment Score?
In this course, we have created and used the `finbert_sa.py` file which is designed to perform sentiment analysis using the finBERT model. This file imports essential libraries like pandas, transformers, and PyTorch to handle data, tokenise text, and load the FinBERT model. This allows traders to focus on interpreting results, rather than setting up complex code.
Functions Used in the `finbert_sa.py` File to Generate Sentiment Score
- load_model(): This function loads the pre-trained FinBERT model, enabling it to perform sentiment analysis on your data.
- predict_overall_sentiment(): This function takes a text input and returns an overall sentiment score for that specific input.
What if you had to analyse multiple sentences?
The process_sentences() function processes multiple sentences at once, making it convenient to analyse sentiment from longer texts or transcripts.
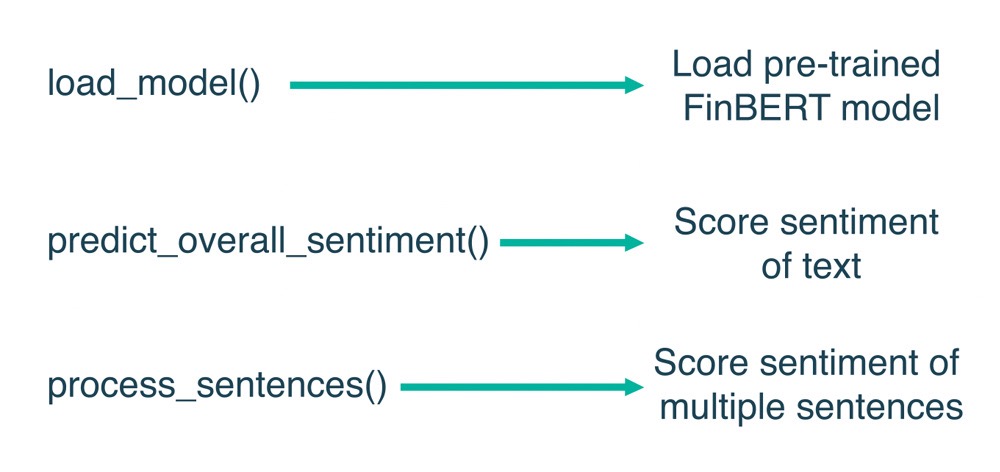
Figure: Functions Present in finBERT File
Example Usage of FinBERT for Sentiment Scoring
Let’s consider the sentence: “The earnings report turned the sentiment bullish.”
In this case, we use the predict_overall_sentiment() function from the ‘finbert_sa.py’ Python file to analyse the sentiment of this sentence. The model generates a sentiment score of 0.1 for this input, indicating a slightly positive sentiment.

Figure: Sentiment Score Generation Using FinBERT
Last but not least, there are frequently asked questions that the audience asked Dr. Medina and the expert answers were given by him which we will take a look at next.
FAQs
These questions are as follows:
Q: Can we use deep learning to train a time series model or is it possible to train a deep learning model with time series data?
A: Yes it is very much possible to train a time series model. As you can see in the image below, data is taken in various formats for training. There is a foundation model which centralises all the information to perform the downstream tasks.
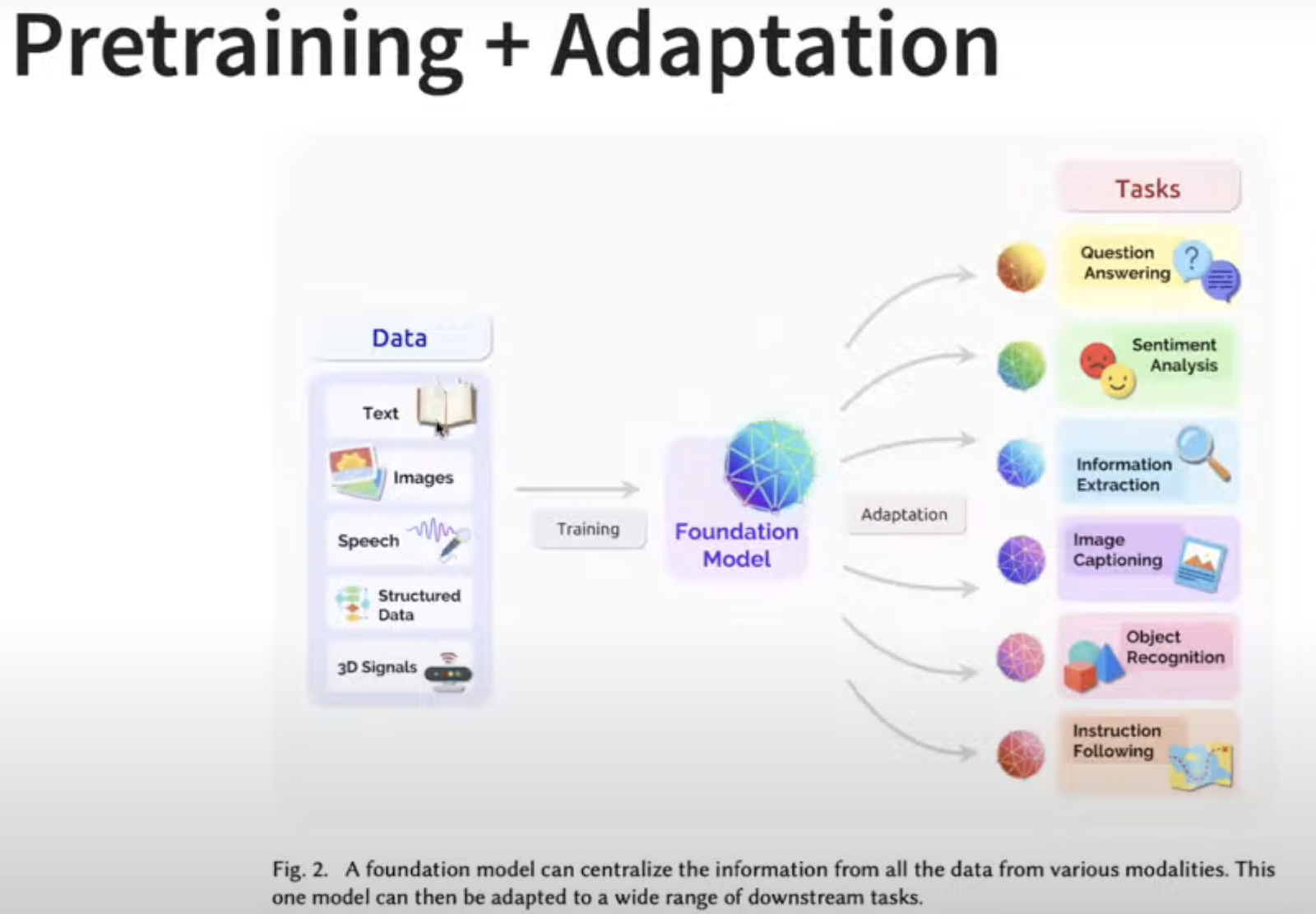
This way some patterns are learnt and it can help you predict the time series that you have. One way is to put the TimeGPT to use which is a GPT in which time is included. Lama is a model that is built in open source.
Q: How were the labels for the FinBERT model created during training or fine-tuning—are they based on human annotations, real market movements, or something else?
A: The sentiment analysis in this case is based on a combination of human input and financial expertise. The sentences were evaluated by human annotators with a background in economics and finance. These annotators were asked if they believed the sentiment in each sentence would have a positive impact on a company’s stock price, but they did not look at the actual stock price movement when making their assessments.
The key point is that the annotators were asked to predict how the sentiment would affect the stock price based on their judgement, without verifying what happened in the market. This avoids bias from knowing the real outcome.
The process involved multiple annotations for each sentence, and a majority vote was used to determine the final sentiment score. In summary, it was a mix of human judgement about potential stock price impact without checking the actual price movement to ensure an unbiased assessment.
Q: How many samples are needed to train a successful transformer-based deep learning model?
A: In finance, the performance of large language models (LLMs) improves as you increase the amount of data and the size of the model. There's a concept called the "scaling law," which suggests that the model's performance can be predicted based on the data size, model size, and computing time used for training. This is fascinating because it provides a more structured way to enhance LLM performance.
However, in finance, the situation is more complex. Financial data has a low signal-to-noise ratio, meaning useful information is often buried in noise. Moreover, financial time series are non-stationary, meaning the patterns in data can change quickly, making it challenging to model future behaviour based on past data.
To give perspective, training an LLM for financial applications requires a massive amount of data—typically high-frequency data—to match the size of models, which can have up to 70 billion parameters. Medina references a study where a transformer model was successfully applied with just 10 million parameters and used daily data over 20 years, showing that while smaller models with less data can perform well, achieving balance is key when applying LLMs in finance.
Conclusion
Incorporating large language models (LLMs) into trading strategies offers innovative ways to leverage generative AI and sentiment analysis in finance. These models, like FinBERT and Whisper, help transform qualitative data, such as news articles or FOMC transcripts, into actionable insights that enhance market predictions and strategy development. By utilising tools specifically fine-tuned for financial data, professional traders can effectively gauge market sentiment and adjust trading positions accordingly. This approach marks a significant shift in modern finance, allowing for more precise predictive modelling and risk management using cutting-edge AI technologies.
If you are ready to explore the power of generative AI in finance, learn how to apply LLMs and sentiment analysis to your trading strategies. Start your journey today with Trading with LLM!
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis..

