
By Udisha Alok
The human mind is an amazing place. Umpteen ideas originate there in a split second, coloured with various emotions. Many such thoughts and emotions are splattered across the ‘walls’ and ‘feeds’ of increasingly popular social media platforms.
In the quest to find the elusive alpha, data scientists and quant analysts have now shifted their focus on processing the tons of ‘big data’ churned out there by internet users. Using programs to understand and analyse the human language is called natural language processing (NLP).
In this post, we’ll look at one of the popular libraries for natural language processing in Python- spaCy.
The topics we will cover are:
- What is spaCy?
- How to install spaCy?
- NLTK vs spaCy
- spaCy trained pipelines
- Tokenization using spaCy
- Lemmatization using spaCy
- Split Text into sentences using spaCy
- Removing punctuation using spaCy
- Removing stop words using spaCy
- POS tagging using spaCy
- Named Entity Recognition using spaCy
- Dependency Visualization using displaCy
- Getting linguistic annotations using spaCy
- spaCy examples on Github
What is spaCy?
spaCy is a free, open-source library for natural language processing in Python. It is one of the two most popular libraries for NLP, the other one being NLTK. We will look at the important differences between the two in a later section.
The spaCy website describes it as the preferred tool for “industrial strength natural language processing”. The rich features offered by spaCy make it an excellent choice for NLP, information extraction, and natural language understanding.
The key advantage of spaCy is that it is designed to work with large amounts of data in an optimal and robust manner.
How to install spaCy?
The simplest way to install spaCy is to follow the following steps:
- Open this page from spaCy’s website on your browser.
- Select the appropriate options for the operating system, platform, package manager, etc.
- The appropriate commands will be displayed in the black panel under the options. Click on the ‘Copy’ icon on the lower right corner of the black panel to copy the installation commands, and paste them on your terminal/command prompt.
Note: If you are doing the installation from a Jupyter notebook, don’t forget to prefix the commands with a ‘!’ sign.
NLTK vs spaCy
Natural Language Toolkit (NLTK) is the largest natural language processing library that supports many languages. Let us compare NLTK and spaCy.
|
S.No. |
NLTK |
spaCy |
|
1. |
NLTK is primarily designed for research. |
spaCy is designed for production use. |
|
2. |
NLTK provides support for many languages. |
Currently, spaCy provides trained pipelines for 23 languages and supports 66+ languages. |
|
3. |
NLTK follows a string processing approach and has a modular architecture. |
spaCy follows an object-oriented approach. |
|
4. |
NLTK provides a large number of different NLP algorithms and hence is preferred for research and building innovative solutions. The user can select a particular algorithm from the available options for a particular task. |
spaCy uses the best algorithm for a particular task. The user does not have to select an algorithm. |
|
5. |
NLTK can be slower. |
spaCy is optimized for speed. |
|
6. |
It is built using Python. |
It is built using Cython. |

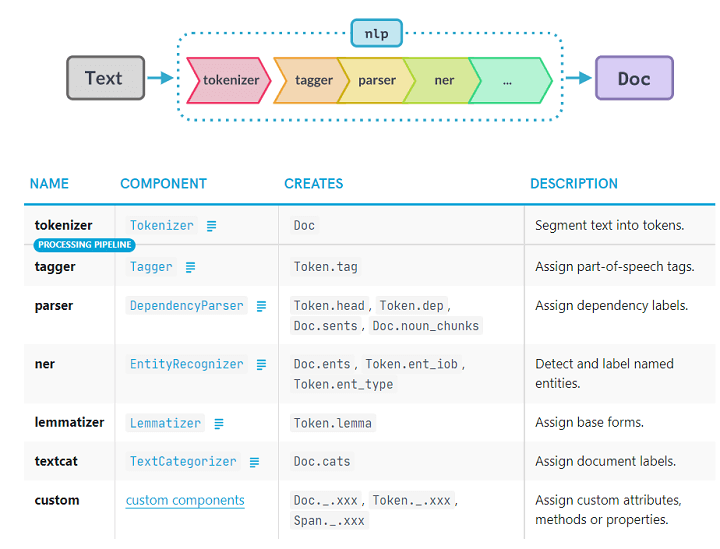
spaCy trained pipelines
spaCy introduces the concept of pipelines. When you pass a text through a pipeline, it goes through different steps (or pipes) of processing. The output from one step (or pipe) is fed into the next step (or pipe).
spaCy offers many trained pipelines for different languages. Typically, a trained pipeline includes a tagger, a lemmatizer, a parser, and an entity recognizer.
We can also design our own custom pipelines in spaCy.
Getting started with spaCy
Let us now do some natural language processing and see how some of these components work in the next few sections.
We need to have installed spaCy and the trained model that we want to use. In this blog, we will be working with the model for the English language, the en_core_web_sm.
Tokenization using spaCy
Passing a text to a trained model produces the doc container. Though it may appear to be similar to the text, the doc contains valuable metadata related to the text.
Yes, I know! You can’t spot any difference between the text and the doc from the above code snippet. But let us explore a bit more.
Okay, so the length is different. What else? Let us now print the tokens from the doc.
The output for the above line of code is:
Jennifer
is
learning
quantitative
analysis.
We have now seen that the doc container contains tokens. Tokens are the basic building blocks of the spaCy NLP ecosystem. They may be a word or a punctuation mark.
Tokenization is the process of breaking down a text into words, punctuations, etc. This is done using the rules for the specific language whose model we are using.
The tokens have different attributes, which are the foundation of natural language processing using spaCy. We will look at some of these in the following sections.
Lemmatization using spaCy
A lemma is the base form of a token, with no inflectional suffixes. E.g., the lemma for ‘going’ and ‘went’ will be ‘go’. This process of deducing the lemma of each token is called lemmatization.
Output:
I - I
am - be
going - go
where - where
Jennifer - Jennifer
went - go
yesterday - yesterday
. - .
Split text into sentences using spaCy
Source: Exploring Ripple and XRP: What it is, Features, and More
Let us now pass this text to our model and split it into individual sentences.
Removing punctuation using spaCy
Before we proceed further with our analysis, let us remove the punctuations from our text.
Removing stop words using spaCy
We can remove the stop words like and, the, etc. from the text because these words don’t add much value to it for analysis purposes.
For this, we first get the list of all the stop words for that language. There are two ways in which we can do it.
This is the second method.
As we can see from the code below, the results of both the above methods are the same.
Now that we have got the list of stop words, let’s remove them from our text.
POS tagging using spaCy
Let us now see how spaCy tags each token with its respective part-of-speech.
If you would like to know more about the different token attributes, please click here.
Named entity recognition using spaCy
What is a named entity? It is any ‘real-world object’ with an assigned name. It may be a country, city, person, building, company, etc. spaCy models can predict the different named entities in a text with remarkable accuracy.
Dependency Visualization using displaCy
Adding another powerful functionality to it’s arsenal, spaCy also comes with a built-in dependency visualizer valled displaCy that lets you check your model's predictions in your browser.
To use it from the browser, we use the ‘serve’ method. DisplaCy can auto-detect if you are working on a Jupyter notebook. We can use the ‘render’ method to return markup that can be rendered in a cell.
Let us try the spaCy’s entity visualizer to render the NER results we got above.
For this, let us import displaCy which is ‘a modern and service-independent visualisation library’
Output:

Getting linguistic annotations using spaCy
You can get insights into the grammatical structure of a text using spaCy’s linguistic annotations functionality. It basically tells you the part of speech each word belongs to and how the different words are related to each other.
We need to have installed spaCy and the trained model that we want to use. In this blog, we’ll work with the English language model, the en_core_web_sm.
Let’s look at an example.
Let’s visualize the syntactic relationship between the different tokens.
Output:

spaCy examples on Github
We’ve covered some of the basic NLP techniques using the spaCy library. To delve into further details, you can head to the spaCy GitHub page where you can find tons of examples to help you in your journey into the spaCy universe.
In addition to the development techniques, you can also try out the extensive test suite offered by spaCy which uses the pytest framework.
Conclusion
We’ve explored some of the main features of spaCy, but there is a lot more to be explored in this powerful Python natural language processing library. I hope that this blog has gotten you started with the initial few steps of this journey. So go ahead and explore the enormous world of human language and thoughts!
Want to harness alternate sources of data, to quantify human sentiments expressed in news and tweets using machine learning techniques? Check out this course on Trading Strategies with News and Tweets. You can use sentiment indicators and sentiment scores to create a trading strategy and implement the same in live trading.
Till then, happy tweeting and Pythoning!
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.
