
Machine learning has become a hot topic today, with entrepreneurs all across the world switching to machine learning for business operations. Machine learning has reached the advancement where it can even predict outcomes without being explicitly programmed to do so.
This is not only it, but there is a lot more when it comes to the applications of machine learning in trading. With this blog, you will learn all about the basics of machine learning and how to begin learning the same along with the resources for learning, the applications of the same and much more!
Dive into this interesting blog which covers:
- What is machine learning?
- Example of machine learning
- History of machine learning
- Importance of machine learning
- Components of machine learning
- Machine learning classification
- Difference between machine learning and deep learning
- Prerequisites to learn machine learning
- Python libraries for machine learning
- Common terms used in machine learning
- Application of machine learning in trading
- Resources to learn machine learning
- The future of machine learning
What is machine learning?
Machine Learning, as the name suggests, provides machines with the ability to learn autonomously based on experiences, observations and analysing patterns within a given data set without explicitly programming.
When we write a program or a code for some specific purpose, we are actually writing a definite set of instructions which the machine will follow.
Whereas in machine learning, we input a data set through which the machine learns by identifying and analysing the patterns in the data set. Then, the machine will make decisions autonomously based on its observations and learnings from the dataset.
Before delving deep into the world of machine learning for trading, let's begin by gaining a solid understanding of the fundamental terms in machine learning for trading.
Example of machine learning
Although there are numerous examples of machine learning, we are covering just a few here.
- Facebook: For instance, think of Facebook’s facial recognition ⁽¹⁾ algorithm which prompts you to tag photos whenever you upload a photo.
- Alexa, Cortana, and other voice assistants: Another example is of the voice assistants who use machine learning to identify and service the user’s request.
- Tesla automobiles: One more example is of Tesla’s autopilot ⁽²⁾ feature.
Now let us see an example of a “bird species recognition learning” problem. This example is explained with the task of the model, the performance measure of the model and the training experience required for the accurate results:
- The task of the machine learning model: Recognizing and classifying species of birds within images
- Performance measure: Percent of bird species correctly classified
- Training experience of the machine learning model: Training on a data-set of bird species with given classifications
Hence, the machine learning model will learn the task according to the performance measure and the required training experience of the machine learning model.
History of machine learning
Machine learning is not a recent phenomenon. In fact, neural networks were first introduced in the year 1943 ⁽³⁾!
Although in the early days, progress in machine learning was somewhat slow due to the high cost of computing. The high computing cost made this domain only accessible to large academic institutions or multinational corporations. Also, the data in itself was difficult to acquire for a company’s needs.
But with the advent of the internet, we are now generating quintillions of data everyday ⁽⁴⁾!
Couple that with the reduction in the price of computations and we find that machine learning is more than a viable proposition ⁽⁵⁾.
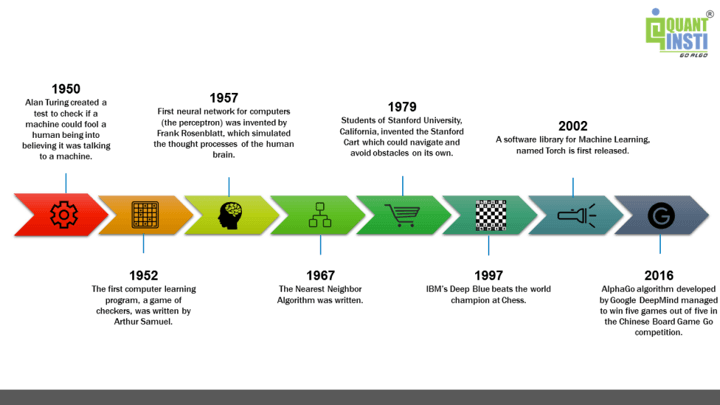
Some of the notable events in the history of machine learning are:
- 1950 - This was the first time when “Alan Turing” ⁽⁶⁾ created a test in order to check if a machine could fool a human being into believing that it was talking to a machine.
- 1952 - The first computer learning program, a game of checkers, was written by Arthur Samuel.
- 1957 - The first neural network for computers was invented by Frank Rosenblatt, which simulated the thought process of a human brain.
- 1967 - The Nearest Neighbor algorithm was written.
- 1979 - Students of Stanford University, California invented the Stanford cart which could navigate and avoid obstacles on its own.
- 1997 - IBM’s Deep Blue beats the world champion at Chess.
- 2002 - A software library for machine learning named Torch was first released.
- 2016 - AlphaGo algorithm developed by Google DeepMind managed to win five games out of five in the Chinese Board Game Go competition.
These events can be represented as:
Importance of machine learning
Machine learning plays an important ⁽⁷⁾ role in the field of enterprises as it enables entrepreneurs to minimise manual efforts. The machine learning model learns with the help of humans but eventually, the machine learns and takes over the learnt task.
Although a minimum level of intervention is needed for making sure that no “machine-related” glitch arises or for updating the data inputted.
Nowadays leading companies like Google, Amazon, Facebook, Tesla, and many more are efficiently utilising these technologies. Hence, machine learning is proving to become a core part of operation and functioning.
Moreover, there are a multitude of use cases that machine learning can be applied to in order to cut costs, mitigate risks, and improve overall quality of life including risk management. Furthermore, the global machine learning (ML) market is expected to grow ⁽⁸⁾ from $21.17 billion in 2022 to $209.91 billion by 2029, at a CAGR of 38.8% in forecast period.
Components of machine learning
There are tens of thousands of machine learning algorithms and hundreds of new algorithms are developed every year.
Every machine learning algorithm has three components:
- Representation: This implies how to represent knowledge. Examples include decision trees, sets of rules, instances, graphical models, neural networks, support vector machines, model ensembles and others.
- Evaluation: This is the way to evaluate candidate programs (hypotheses). Examples include accuracy, prediction and recall, squared error, likelihood, posterior probability, cost, margin, entropy k-L divergence and others.
- Optimization: Last but not the least, optimization is the way candidate programs are generated and is known as the search process. For example, combinatorial optimization, convex optimization, and constrained optimization.
All machine learning algorithms are a combination of these three components and a framework for understanding all algorithms.
Machine learning classification
Machine Learning algorithms can be classified into:
- Supervised Algorithms:
◦ Linear Regression,
◦ Logistic Regression,
◦ KNN classification,
◦ Support Vector Machine (SVM),
◦ Decision Trees,
◦ Random Forest,
◦ Naive Bayes’ theorem - Unsupervised Algorithms: K Means Clustering
- Reinforcement Algorithm
Let us dig a bit deeper into these machine learning basics algorithms.
Supervised Machine Learning Algorithms
In this type of algorithm, the data set on which the machine is trained consists of labelled data or simply said, consists of both the input parameters as well as the required output.
Let’s take the previous example of facial recognition and once we have identified the people in the photos, we will try to classify them as babies, teenagers or adults.
Here, babies, teenagers and adults will be our labels and our training dataset will already be classified into the given labels based on certain parameters through which the machine will learn these features and patterns and classify some new input data based on the learning from this training data.
Supervised Machine Learning Algorithms can be broadly divided into two types of algorithms; Classification and Regression.
Classification Algorithms
Just as the name suggests, these algorithms are used to classify data into predefined classes or labels. We will discuss one of the most used classification algorithms known as the K-Nearest Neighbour (KNN) Classification Algorithm.
Regression Machine Learning Algorithms
These algorithms are used to determine the mathematical relationship between two or more variables and the level of dependency between variables. These can be used for predicting an output based on the interdependency of two or more variables.
For example, an increase in the price of a product will decrease its consumption, which means, in this case, the amount of consumption will depend on the price of the product.
Here, the amount of consumption will be called the dependent variable and the price of the product will be called the independent variable. The level of dependency on the amount of consumption on the price of a product will help us predict the future value of the amount of consumption based on the change in prices of the product.
Unsupervised Machine Learning Algorithms
Unlike supervised learning algorithms, where we deal with labelled data for training, the training data will be unlabelled for Unsupervised Machine Learning Algorithms. The clustering of data into a specific group will be done on the basis of the similarities between the variables.
Some of the unsupervised machine learning algorithms are K-means clustering and neural networks.
A simple example would be that given the data of football players, we will use K-means clustering and label them according to their similarity. Thus, these clusters could be based on the striker's preference to score on free kicks or successful tackles, even when the algorithm is not given pre-defined labels to start with.
K-means clustering would be beneficial to traders who feel that there might be similarities between different assets which cannot be seen on the surface.
While we did mention neural networks in unsupervised machine learning algorithms, it can be debated that they can be used for both supervised as well as unsupervised learning algorithms. You can learn all about in this course on unsupervised learning course. Artificial neural network and Recurrent Neural networks also fall under unsupervised machine learning algorithms.
Reinforcement Machine Learning Algorithms
Reinforcement learning is a type of machine learning in which the machine is required to determine the ideal behaviour within a specific context, in order to maximise its rewards.
It works on the rewards and punishment principle which means that for any decision which a machine takes, it will be either rewarded or punished. Thus, it will understand whether or not the decision was correct.
This is how the machine will learn to take the correct decisions to maximise the reward in the long run.
For a reinforcement algorithm, a machine can be adjusted and programmed to focus more on either the long-term rewards or the short-term rewards. When the machine is in a particular state and has to be the action for the next state in order to achieve the reward, this process is called the Markov Decision Process.
Difference between machine learning and deep learning

Machine Learning models lack the mechanism to identify errors, in such cases the programmer needs to step in to tune the model for more accurate decisions, whereas deep learning models can identify the inaccurate decision and correct the model on its own without human intervention.
But for doing so, deep learning models require a huge amount of data and information, unlike Machine Learning models.
Prerequisites to learn machine learning
There are some prerequisites to learning machine learning without which one will be deprived of the important concepts needed to proceed with learning the same. These are:
Statistical concepts
Statistical concepts are essential in machine learning to create models from data. Statistics such as analysis of variance and hypothesis testing are crucial for building algorithms.
Probability
Probability helps in predicting future consequences, and the majority of the algorithms in machine learning are based on uncertain conditions where reliable decisions are needed.
Data Modelling
Data modelling enables identifying the underlying data structures, finding out the patterns and filling the gaps between the places where data is nonexistent.
Programming Skills
We are all aware that machine learning mostly depends on algorithms, which means one should possess sound knowledge of at least one of the programming languages. Python is considered an easy language to master, and also, is used by most of the quants.
Python libraries for machine learning
Python libraries help with eliminating the need to write code from scratch. They play a vital role in developing machine learning models as they need algorithms. Let us take a look at some of the most popular libraries below.
Scikit-learn
It is a Python Machine Learning library built upon the SciPy library and consists of various algorithms including classification, clustering and regression, and can be used along with other Python libraries like NumPy and SciPy for scientific and numerical computations.
Some of its classes and functions are sklearn.cluster, sklearn.datasets, sklearn.ensemble, sklearn.mixture etc.
TensorFlow
TensorFlow is an open-source software library for high-performance numerical computations and machine learning applications such as neural networks. It allows easy deployment of computation across various platforms like CPUs, GPUs, TPUs etc. due to its flexible architecture. Learn how to install TensorFlow GPU here.
Keras
Keras is a deep learning library used to develop neural networks and other deep learning models. It can be built on top of TensorFlow, Microsoft Cognitive Toolkit or Theano and focuses on being modular and extensible.
Common terms used in machine learning
Here are a few machine learning basics terms which would be of help as you start your journey in machine learning algorithms.
Bias
A machine learning model is said to have a low bias if its predictability level is high. In other words, it makes fewer mistakes when it is working on a dataset.
Bias plays an important role when we have to compare two machine learning algorithms for the same problem statement.
Cross-validation bias
Cross-validation in machine learning is a technique that provides an accurate measure of the performance of a machine learning model. This performance implies your expectation when the model is used in the future without the help of any human.
In short, the cross-validation bias finds out if the machine learning model has learnt the task properly or not.
The application of the machine learning models is to learn from the existing data and use that knowledge to predict future unseen events. The cross-validation in the machine learning model needs to be thoroughly done before live trading so that no unexpected mistakes are made.
Underfitting
If a machine learning model is not able to predict with a decent level of accuracy, then we say that the model underfits. This could be due to a variety of reasons, including, not selecting the correct features for the prediction, or simply the problem statement is too complex for the selected machine learning algorithm.
Overfitting
In both machine learning and statistics, overfitting occurs when the model fits the data too well or simply put when the model is too complex. Overfitting model learns the detail and noise in the training data to such an extent that it negatively impacts the performance of the model on new data/test data.

Overfitting problem can be solved by decreasing the number of features/inputs or by increasing the number of training examples to make the machine learning algorithms more generalised. The more common way of solving the overfitting problem is by regularisation.
These were a few terms we discussed in Machine learning basics. Most of the popular machine learning algorithms are mentioned above.
Application of machine learning in trading
Machine learning is applied to a variety of services. Machine learning plays an important role in the field of enterprises as it enables entrepreneurs to understand customers’ behaviour and business functioning behaviour.
At present, almost every common domain is powered by machine learning applications. To name a few such industries – healthcare, search engine, digital marketing, and education are the major beneficiaries.
Let us see specifically, which all services the machine learning system covers.

Through this video, you can discover how machine learning transforms the way we analyze, predict, and execute trades. A comprehensive guide you through the process of designing and creating a machine learning strategy that can be implemented in live markets. Leverage data-driven decision-making with machine learning and its applications in the world of trading!
Resources to learn machine learning
Various resources are available to learn machine learning concepts. To learn from basics to advanced, concepts, terminologies, projects and more, you can check out these blogs on machine learning.
Let us see some other resources below.
Courses
First of all, let us see which courses can be explored for learning machine learning. Here is a list:
Learning Track: Machine Learning & Deep Learning in Financial Markets
The courses in the learning tracks cover everything from simple to complex models.
Hence, be it a beginner or an expert wanting to move to the next advanced step, this learning track is suitable for all.
With the courses, you will learn:
- Tuning hyperparameters
- Gradient boosting
- Ensemble methods
- Advanced techniques to make robust predictive models
- To use unsupervised learning in trading to enhance the algorithms
Python for Machine Learning in Finance
The course is perfect for those looking to get started on using Python for machine learning. With this course, you will get a step-by-step guide on creating machine learning algorithms for trading.
Also, you can evaluate the performance of the machine learning algorithm and perform backtest, paper trading and live trading with Quantra’s integrated learning.
Videos
Machine Learning for Trading by Dr. Ernest Chan
Before giving the introduction to the video, let us first know a bit about Dr. Chan.
Dr. Chan is a well-renowned global personality in the domain of Algorithmic and Quantitative Trading. He is the Managing Member of QTS Capital Management, LLC. Also, he has worked for various investment banks (Morgan Stanley, Credit Suisse, Maple) and hedge funds (Mapleridge, Millennium Partners, MANE) since 1997.
In this video, Dr. Ernest Chan answers some of the most asked questions on machine learning for trading, brought to you by QuantInsti.
Machine Learning For Traders: An Introduction
This video is apt for those who want to know what machine learning is and the difference between a regular algorithm in a programming language (Python, C++, etc.) and a machine learning algorithm.
Also, this video includes examples of machine learning (ML) algorithms in the real world, industries using machine learning and implementation and usage of machine learning in trading.
Machine Learning For Traders: Terminologies
In this video, we discuss certain terms in machine learning. They are training and testing data sets. This video will also help you learn the types of machine learning tasks namely-
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Machine Learning For Traders - An Introduction To Classification
In this video, you will learn the following points:
- Introduction to Classification
- Application in various fields such as:
- Medical Diagnosis
- Fraud detection
- Handwriting recognition
- Customer segmentation
- Risk assessment
- An example of a Classification used by E-Commerce websites
- It is not restricted to text and numbers, even images can be classified
- Supervised classifier algorithms
- The classifier algorithms can be chosen, depending on
- Size of training data
- Independence of features set
- System speed
Also, the classifier algorithms covered in this video are:
- K-Nearest Neighbours Algorithm (KNN)
- Random Forests Using Decision Trees
- Artificial Neural Networks (ANN)
- Naive Bayes Classification
Books
Further, and lastly, there are some useful books which can help you learn all about machine learning. Books are a great source of learning for those who enjoy reading for learning purposes. Also, those who want to learn the concepts with much more detailed explanations can opt for books when it comes to learning.
The future of machine learning
Machine learning is a versatile and powerful technology. The future of machine learning is exceptionally exciting.
Machine learning could be a contested merit to an enterprise or an organisation as tasks that are presently being done manually shall be wholly accomplished by the machines in the future.
As per the report ⁽⁹⁾, the machine learning (ML) market size was USD 15.44 billion in 2021. The market size is expected to rise from USD 21.17 billion in 2022 to USD 209.91 billion by 2029 at a CAGR of 38.8% during the forecast period.
Bibliography
- Solomonoff, R.J. (June 1964). "A formal theory of inductive inference. Part II" ⁽¹⁰⁾. Information and Control.
- Mitchell, Tom (1997) ⁽¹¹⁾. Machine Learning ⁽¹²⁾. New York: McGraw Hill.
- Cortes, Corinna ⁽¹³⁾; Vapnik, Vladimir N. (1995). "Support-vector networks". Machine Learning ⁽¹⁴⁾.
- Stuart J. Russell, Peter Norvig (2010) Artificial Intelligence: A Modern Approach ⁽¹⁵⁾, Third Edition, Prentice Hall.
Conclusion
Machine learning, being so important for various fields, has gained popularity for all the right reasons. By learning about the prerequisites and adopting the same, one can use machine learning. Also, the future of machine learning seems to be bright. Hence, learning all about the famous machine learning has several advantages.
Begin your journey in the world of machine learning with our course on Introduction to machine learning and become an expert in using machine learning algorithms.
Artificial intelligence in trading enhances these algorithms by analyzing vast amounts of market data in real time, improving decision-making and optimizing trading strategies. Integrating AI with machine learning allows traders to gain a competitive edge through more accurate predictions.
With the help of several important research studies in the domain, this course helps you find out how different machine learning algorithms are implemented on financial markets data.
Note: The original post has been revamped on 26th September 2022 for accuracy, and recentness.
Disclaimer: All investments and trading in the stock market involve risk. Any decision to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.
