
By Naman Swarnkar
In this article, we will study some of the most widely used features of NLTK and use them in building a sentiment analysis model. Dealing with natural language data and processing it is the core of News based automated trading systems and thus an exciting skill from an algorithmic trader's perspective.
We would recommend brushing up on your Python skills to get the best out of this article. You can read some of our previous articles like Python for trading, Python libraries or check out our Python for trading course to learn in a structured manner through interactive coding exercises.
Here are the topics we will be covering:
- How to install NLTK
- NLTK Corpus
- NLTK VADER Sentiment Analysis
- NLTK Tokenizers
- NLTK Stopwords
- NLTK Stemmers
- Train Sentiment Analysis model
NLTK, an acronym for Natural Language Toolkit, was developed by researchers at the University of Pennsylvania in an attempt to support their research on NLP back in 2001. Since then, NLTK has been widely adopted by researchers and NLP practitioners around the globe. It is an open-source library written in Python with large community support. The developers of NLTK claim it provides easy to use interfaces to over 50 resources which covers all your needs in language processing.
How to install NLTK
One can install NLTK by using the pip package installer. Recently NLTK has dropped support for Python 2 so make sure that you are running Python 3.5 and above. Check the installed version of Python and install NLTK by running the code provided below.
3.7.4
To brush up on the basics of Python, you can enrol for the Python for Trading course on Quantra. Now that we are done with the installation, let’s proceed to explore the NLTK library.
NLTK Corpus
At the heart of every natural language processing project is a large collection of text data. This is also known as Corpus. Although text data is readily available, it is not always present in a structured format. This is a peculiar aspect of NLP making it a challenging field to pursue.
NLTK, apart from various tools, also provides access to carefully curated and annotated text corpora available in many languages. A non-exhaustive table of corpora available in NLTK is listed here. We’ll be using one such corpus, named ‘twitter_samples’ in this post.
As the name suggests, it is a collection of tweets. The corpus contains 3 files and data is stored in JSON format. Two of them are labelled as ‘positive’ and ‘negative’ representing their sentiment.
The third file contains tweets collected from the public stream of Twitter's Streaming API using the following keywords: "david cameron, miliband, milliband, sturgeon, clegg, farage, tory, tories, ukip, snp, libdem". More details about this in the readme file stored at the corpus location on your disk. A quick google search tells that these tweets are from the UK's 2015 pre-election period.

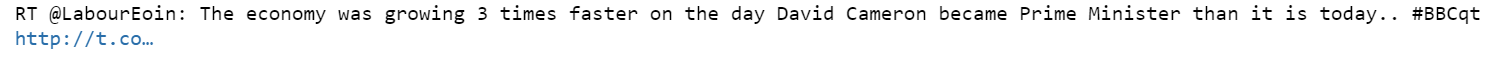
Tweets usually contain hashtags, hyperlinks, etc. We'll remove these add-ons and use only text to label the sentiment of tweets so that they can be used to create a sentiment analysis model. The flowchart below explains the flow of the process.

Introducing Tweet Preprocessor
Tweet preprocessor is a fully customizable and free python library that can be used to clean tweets. We'll remove hashtags, URLs, mentions, and retweet text from tweets using the library. We'll keep emoticons as they help gauge the sentiment. The library is not a part of NLTK and can be installed using the pip package installer.
You can install it in the Anaconda command prompt as follows

Alternatively, you can install it in the jupyter notebook
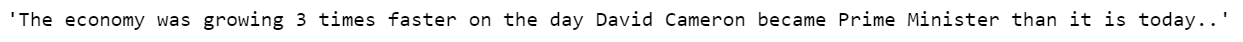
We'll do the same for all tweets and store it in a list.
NLTK VADER Sentiment Analysis
Labelling the sentiment of text data is an exhausting process. We can automate this process using the VADER sentiment analysis module to create our custom dataset. Study shows that VADER performs as good as individual human raters at matching ground truth. You can read more about VADER here.
Now that we have extracted text from tweets, we'll use VADER to gauge sentiment and label them accordingly using generated compound sentiment scores. We can also set a threshold for sentiment classification.
Congrats! We have created a custom labeled political news dataset. We'll now create Bag of Words vectorized representation of these tweets so that they can be used by machine learning models to train a sentiment analysis model.
NLTK Tokenizers
Tokenization is the process of splitting text data into individual tokens by locating word boundaries. This is an important step in pre-processing text data. Generated tokens can then be used for feature extraction. This may include removing/masking sensitive data, counting frequency, removing stopwords and punctuations, stemming and lemmatization, and so on.
NLTK provides a number of tokenizers, each built for its own custom application. We'll use tweet tokenizer that has added functionality of reducing the length of tweet apart from converting text into lower case.

NLTK Stopwords
Stop words include common occurring words such as ‘the’, ‘is’, etc that do not add meaning to sentences. Stop words are not exhaustive and one can specify custom stop words while working on their NLP model.
NLTK comes with a list of stopwords that serves as a collection of most commonly used stopwords and can be readily used.
NLTK Stemmers
Stemming is a word normalization process that aims at reducing words into their root form by stripping the suffix. This often results in words that do not carry any meaning. For example, the stemmed form of 'efficiencies' and 'efficiency' is 'effici'. Stemming is a rule-based approach and as such, there is no standard procedure defined.
There are various stemmers available in NLTK. Porter stemmer is one of the famous stemmers out there and is used widely. We'll use Snowball Stemmer which is also known as Porter2 and is a little stricter with rules.
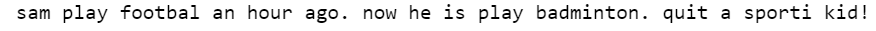
Notice how two different words 'played' and 'playing' are reduced to 'play'. We'll now define a function that takes a tweet as input and performs the following steps:
- Tokenizes the tweet
- Removes stopwords and punctuations
- Returns a tweet with the stemmed form of the words
Train Sentiment Analysis model
We'll use the cleaned tweets to create their bag of words vectorized representation using Sklearn's CountVectorizer. We'll perform a stratified train_test_split of the dataset before that to ensure that our classes get equivalent representation in the train and test set. Finally, we'll train a logistic regression model to classify those tweets.
Let's print accuracy score and classification report to see the model's performance.
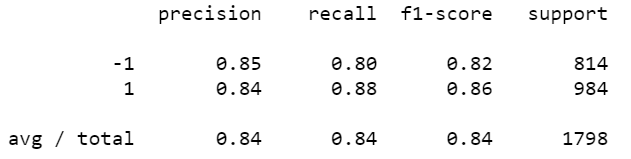
The Accuracy Score is not a good metric to gauge the performance of a binary classification model trained on an imbalanced dataset. Precision and Recall are better metrics for such datasets and are calculated for each class separately. There is a trade-off between these metrics and one cannot maximize both of them simultaneously. Depending on the problem, we chose either of them.
F1 score is the harmonic mean of these two metrics and is often used as an alternative to accuracy score. F1 score of 0.84 suggests that the model is faring quite well in classifying tweets and hence gauging the sentiment of tweets. Read more about these metrics here.
One can work on to improve the model by using more data, creating a balanced dataset, using better word embedding models like Word2Vec, and retaining more information from tweets. Also, try to experiment with the threshold used for labelling original tweets. VADER is prone to errors and may require scrutiny. Remember that your model is as good as the data. If you want to learn how to use different models such as Word2Vec, BERT etc for sentiment analysis, you can always check the course on Natural language processing.
Conclusion
News is the prime factor that affects the prices of financial assets. Automating news retrieval and creating sentiment analysis models to quantify news into trading signals helps in creating better trading opportunities.
You have seen how to create a custom dataset and use it to train a sentiment analysis model with the help of NLTK. If you are interested in all the applications of the NLTK library, you can check the book authored by the creators of NLTK for free on this link. You can further learn about downloading news from twitter, creating datasets and trading strategies using sentiment analysis models in the course Trading Strategies with News and Tweets.
References
- Tweet pre-processor
- Natural Language Processing with Python, by Steven Bird, Ewan Klein, and Edward Loper.
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.

