
By José Carlos Gonzáles Tanaka
In this blog, I want to present one of the advanced data analysis techniques available in Python to the quant trading community to support their research ambitions. It has been done in a simple and hands-on manner. You can find the TGAN code on GitHub as well.
Why TGAN?
You’ll encounter situations where daily financial data is insufficient to backtest a strategy. However, synthetic data, following the same real data distribution, can be extremely useful to backtest a strategy with a sufficient number of observations. The Generative adversarial network, a.k.a GAN, will help us generate synthetic data. Specifically, we’ll use the GAN model for time series data.
Blog Objectives & Contents
In this blog, you’ll learn:
- The GAN algorithm definition and how it works
- The PAR synthetizer to use the time-series GAN (TGAN) algorithm
- How to backtest a strategy using synthetic data created with the TGAN algorithm
- The benefits and challenges of the TGAN algorithm
- Some notes to take into account to improve the results
This blog covers:
- What the GAN algorithm is, and how it works
- The PAR synthesizer from the SDV library
- Backtest a machine-learning-based strategy using synthetic data
- Benefits and challenges of the TGAN algorithm
- Some notes regarding the TGAN-based backtesting
Who is this blog for? What should you already know?
For any trader who might deal with scarce financial data to be used to backtest a strategy. You should already know how to backtest a strategy, about technical indicators, machine learning, random forest, Python, deep learning.
You can learn about backtesting here:
- A comprehensive beginner’s guide to backtesting
- A Python-focused hands-on course on backtesting using real market data for serious learners
To learn about machine learning related topics follow the links here:
- Course bundle on machine learning in trading
- Free reading material on machine learning in finance to get you started
If you want to know more about generating synthetic data, you can check this article on Forbes.
What the GAN algorithm is, and how it works
A generative adversarial network (GAN) is an advanced deep learning architecture that consists of two neural networks engaged in a competitive training process. This framework aims to generate increasingly realistic data based on a designated training dataset.
A generative adversarial network (GAN) consists of two interconnected deep neural networks: the generator and the discriminator. These networks function within a competitive environment, where the generator's goal is to create new data, and the discriminator's role is to determine whether the produced output is authentic or artificially generated.
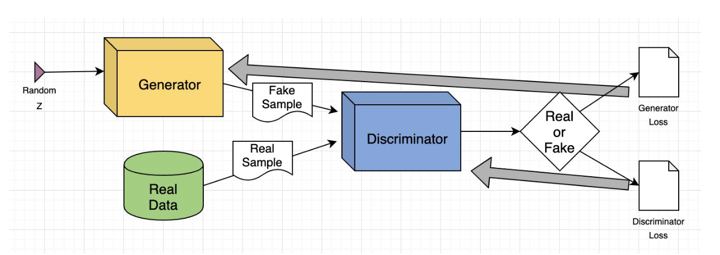
From a technical perspective, the operation of a GAN can be summarized as follows. While a complex mathematical framework underpins the entire computational mechanism, a simplified explanation is presented below:
The generator neural network scrutinizes the training dataset to identify its underlying characteristics. Simultaneously, the discriminator neural network analyzes the original training data, independently recognizing its features.
The generator then alters specific data attributes by introducing noise or random modifications. This modified data is subsequently presented to the discriminator.
The discriminator assesses the likelihood that the generated output originates from the genuine dataset. It then provides feedback to the generator, advising it to minimize the randomness of the noise vector in subsequent iterations.
The generator seeks to enhance the chances of the discriminator making an erroneous judgment, while the discriminator strives to reduce its error rate. Through iterative training cycles, both the generator and discriminator progressively develop and challenge one another until they achieve a state of equilibrium. At this juncture, the discriminator is unable to distinguish between real and generated data, signifying the conclusion of the training process.
In this case, we’ll use the SDV library where we have a special GAN algorithm for time series. The algorithm follows the same procedure from above, but in this time-series case, the discriminator learns to make a similar time series from the real data by making a match between the real and synthetic returns distribution.
The PAR synthesizer from the SDV library
The GAN algorithm discussed in this blog comes from the research paper on “Sequential Models in the Synthetic Data Vault“ by Zhang published in 2022. The exact name of the algorithm is the conditional probabilistic auto-regressive (CPAR) model.
The model uses only multi-sequence data tables, i.e. multivariate time series data. The distinction here is that for each asset price, you’ll need a context variable that will identify the asset throughout the estimation and that does not vary within the sequence datetime index or rows, i.e., these context variables do not change over the course of the sequence. This is referred to as “contextual information”. In the stock market, the industry, and the firm sector denote the asset “context”, i.e., the context that the asset belongs to.
Some things to note about this algorithm are:
- A diverse range of data types is available, including numeric, categorical, datetime, and others, as well as some missing values.
- Multiple sequences can be incorporated within a single dataframe, and each asset can have a different number of observations.
- Each sequence has its own distinct context.
- You’re not able to run this model with a single asset price data. You’ll actually need more than one asset price data.
Backtest a machine-learning-based strategy using synthetic data
Let’s dive quickly into our script!
First, let’s import the libraries
Let’s import the Apple and Microsoft stock price data from 1990 to Dec-2024. We download the 2 stock price data separately and then create a new column named “stock” that will have for all rows the name of each stock corresponding to its price data. Finally, we concatenate the data.
Let’s create a function to create synthetic datetime indexes for our new synthetic data:
Let’s now create a function that will be used to create the synthetic data. The function explanation goes in steps like these:
- Copy the real historical dataframe
- Create the synthetic dataframe
- Create a context column copying the stock column.
- We’ll set the metadata structure. This structure is necessary for the GAN algorithm on the SDV library:
- Here we define the column data type together. We specify the stock column as ID, because this will identify the time series that belong to each stock.
- We specify the sequence index, which is just the Date column describing the time series datetime indexes for each stock price data.
- We set the context column to match the stock column, which serves as a 'trick' to associate the Volume and Returns columns with the same asset price data. This approach ensures that the synthesizer generates entirely new sequences that follow the structure of the original dataset. Each generated sequence represents a new hypothetical asset, reflecting the overarching patterns in the data, but without corresponding to any real-world company (e.g., Apple or Microsoft). By using the stock column as the context column, we maintain consistency in the asset price return distribution.
- We set the ParSynthetizer model object. In case you have an Nvidia GPU, please set cuda to True, otherwise, to False.
- Fit the GAN model for the Volume and price return data. We don’t input OHL data because the model might obtain High prices below the Low data, or Low prices higher than the High prices, and so on.
- Here we output the synthetic data based on a distinct seed. For each seed:
- We specify a customized scenario context, where we define the stock and context as equal so we get the same Apple and Microsoft price return distribution.
- Get the Apple and Microsoft synthetic sample using a specific number of observations named as sample_num_obs
- Then we save only the “Symbol” dataframe in synthetic_sample
- Compute the Close prices
- Get the historical mean return and standard deviation for the High and Low prices with respect to the Close prices.
- Compute the High and Low prices based on the above.
- Create the Open prices with the previous Close prices.
- Round the prices to 2 decimals.
- Save the synthetic data into a dictionary depending on the seed number. The seed discussion will be done later.
The following function is the same described in my previous article on Risk Constrained Kelly Criterion.
The following function is about using a concatenated sample (with real and synthetic data) and:
- Get the input features based on the technical indicators
- Replace Inf values with NaN values
- Create our prediction feature
- Drop NaN values
And this last function is about getting the input features and prediction feature separately for the train and test sample.
Next:
- Set the random seed for the whole script
- Specify 4 years of data for fitting the synthetic model and the machine-learning model
- Set the number of observations to be used to create the synthetic data. Save it as test_span
- Set the initial year for the backtesting year periods.
- Get the monthly indexes and the seeds list explained later.
We create a for-loop to backtest the strategy:
- The for loop goes through each month of the 2024 year.
- It’s a walk-forward optimization where we optimize the ML model parameter at the end of each month and trade the following month.
- For each month, we estimate 20 random-forest algorithms. Each model will be different as per its random seed. For each model, we create synthetic data to be used for the particular ML model.
The for loop steps go like this:
- Specify the current and next month end.
- Define the span between the current and month end datetimes
- We define the data sample up to the next month and use the last 1000 observations plus the span defined above.
- Define 2 dictionaries to save the accuracy scores and the models.
- Define the data sample to be used to train the GAN algorithm and the ML model. Save it in the tgan_train_data variable.
- Create the synthetic data for each seed using our previous function named “create_synthetic_data”. Choose the Apple stock only to be used to backtest the strategy.
- For each seed
- Create a new variable to save the corresponding synthetic data as per the seed.
- Update the Open first price observation.
- Concatenate the real Apple stock price data with its synthetic data.
- Sor the index
- Create the input features
- Split the data into train and test dataframes.
- Separate the input and prediction features from the above 2 dataframes as X and y.
- Set the random-forest algo object
- Fit the model with the train data.
- Save the accuracy score using the test data.
- Get the best model seed once we estimate all the ML models. We select the best random forest model based on the synthetic data predictions using the accuracy score.
- Create the input features
- Split the data into train and test dataframes.
- Get the signal predictions for the next month.
- Continue the loop iteration
The following strategy performance computation, plotting and pyfolio-based performance tear sheet is based on the same article referenced earlier on risk-constrained Kelly Criterion.
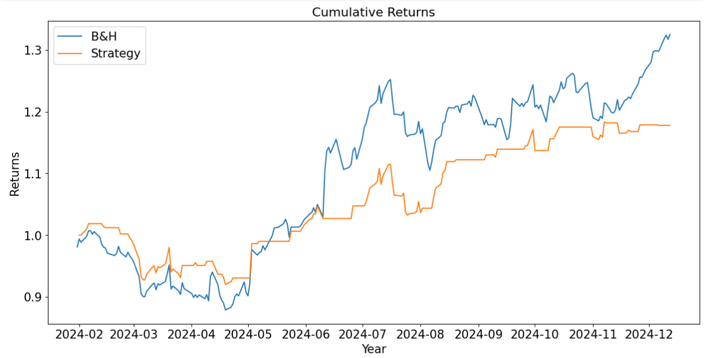
From the above pyfolio results, we’ll create a summary table:
|
Metric |
B&H Strategy |
ML Strategy |
|
Annual return |
41.40% |
20.82% |
|
Cumulative returns |
35.13% |
17.78% |
|
Annual volatility |
22.75% |
14.99% |
|
Sharpe ratio |
1.64 |
1.34 |
|
Calmar ratio |
3.24 |
2.15 |
|
Max Drawdown |
12.78% |
9.69% |
|
Sortino ratio |
2.57 |
2.00 |
We can see that, overall, we get better results using the Buy-and-Hold strategy. Even though the annual return is higher for the B&H strategy, the volatility is lower for the ML strategy using the synthetic data for backtesting; although the B&H strategy has a higher Sharpe ratio. The Calmar and Sortino ratios are higher for the B&H strategy, although we obtain a lower max drawdown with the ML strategy.
Benefits and challenges of the TGAN algorithm
The benefits:
- You can reduce data collection costs because synthetic data can be created based on a lower number of observations compared to having the whole data of a specific asset or group of assets. This allows us not to concentrate on data gathering but on modeling.
- Greater control of data quality. Historical data is only a single path of the entire data distribution. Synthetic data with good quality can give you multiple paths of the same data distribution, allowing you to fit the model based on multiple scenarios.
- Due to the above, the model fitting on synthetic data will be better, and the ML models will have better-optimized parameters.
The challenges:
- The TGAN algorithm fitting can take a long time. The bigger the data sample to train the TGAN, the longer it will take to fit the data. When dealing with millions of observations to fit the algorithm, you’ll face a long time to get it completed.
- Due to the fact that the generator and discriminator networks are adversarial, GANs frequently experience training instability, i.e., the model doesn’t fit the data. To ensure stable convergence, hyperparameters must be carefully adjusted.
- TGAN can tend to model collapse: If there’s an imbalance training between the model’s generator and discriminator, there’s a reduced diversity of samples generated for synthetic data. Hyperparameters, once again, should be adjusted to deal with this issue.
Some notes regarding the TGAN-based backtesting
Please find below some things to improve in the script
- You can improve the equity curve by applying risk management thresholds such as stop-loss and take-profit targets.
- We have used the accuracy score to choose the best model. You could have used any other metric such as the F1-score, the AUC-ROC, or strategy performance metrics such as annual return, Sharpe ratio, etc.
- For each random forest, you could have obtained more than one time series (sequence) for each asset to backtest a strategy for multiple paths (sequences). We did this arbitrarily to reduce the time spent on running the algorithm daily and for demonstration purposes. Creating multiple paths to backtest a strategy would give your best model a more robust strategy performance. That’s the best way to profit from synthetic data.
- We compute the input features for the real stock price multiple times when we can actually do it once. You can tweak the data to do just that.
- The ParSynthetizer object defined in our function called “create_synthetic_data” has an input called “epochs”. This variable allows us to pass the entire training dataset into the TGAN algorithm (using the generator and discriminator). We have used the default value which is 128. The higher the number of epochs, the higher the quality of your synthetic sample. However, please take into account that the higher the epoch number, the longer the time spent for the GAN model to fit the data. You should balance both as per your compute capacity and optimization best time for your walk-forward optimization process.
- Instead of creating the percentage returns for the non-stationary features, you could have used the ARFIMA model applied to each non-stationary feature and use the residuals as the input feature. Why? Check our ARFIMA model blog article.
- Don’t forget to use transaction costs to simulate better the equity curve performance.
Conclusion
The purpose of this blog was to:
- Present you with the TGAN algorithm to research further.
- Show a backtesting code script that can be readily tweaked.
- Discuss the benefits and shortcomings of using TGAN algorithm in trading.
- Suggest next steps to continue working.
To summarize, we applied multiple random forest algorithms each day and selected the best one based on the best Sharpe ratio obtained with the test-data created using synthetic data.
In this case, we used a time-series-based GAN algorithm. Be careful about this, there are many GAN algorithms but few for time-series data. You should use the latter model.
If you are interested in advanced algorithmic trading strategies, we recommend you the following courses
- Executive Programme in Algorithmic Trading: First step to build your career in Algorithmic trading.
- AI in Trading Advanced: Self-paced courses focused on Python.
File in the download:
- The Python code snippets for implementing the strategy are provided, including the installation of libraries, data download, create relevant functions for the backtesting loop, the backtesting loop and performance analysis.
All investments and trading in the stock market involve risk. Any decision to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.
