
Updated by Chainika Thakar (Originally written by Naman Swarnkar)
The world of Natural Language Processing (NLP) is a fascinating field where machines and computers learn to understand and interact with human language. In this journey, we'll unravel the fascinating realm of NLP and its foundation, the Bag of Words (BoW) technique.
In this comprehensive guide, we'll take a journey through the basics of NLP and introduce you to a powerful tool within its arsenal: the Bag of Words (BoW).
To start, we'll discuss a quick overview of NLP and will learn why text analysis is so crucial in this realm. Then, we'll dive into the Bag of Words approach, breaking down its concept, the essential preprocessing steps you'll need to follow, and then we will see the step by step guide in building BoW models from scratch.
Next up, we'll discuss the practical skills to implement BoW in Python. Moreover, we will figure out the key libraries like NLTK and scikit-learn, see how to import data, prepare the text, and construct BoW models. We'll even walk through visualising the BoW representation and provide a code example with a detailed explanation.
But that's not all! We'll also explore the advantages and limitations of the Bag of Words technique, that help make well-informed choices when using it in the NLP projects. We will also discuss some handy tips for supercharging the BoW analysis.
Towards the end of our journey, we'll see the real-world applications of BoW, demonstrating its relevance in sentiment analysis, text classification, and a host of other NLP uses. By the time we're done, you will have a solid grasp of BoW, knowing how to put it to work using Python, and appreciate its significance in the world of text analysis.
Ready to get started? Let's dive in!
Some of the concepts covered in this blog are taken from this Quantra learning track on Natural Language Processing in Trading. You can take a Free Preview of the courses by clicking on the green-coloured Free Preview button.
This blog covers:
- Brief overview of Natural Language Processing
- Importance of text analysis in NLP
- Introduction to the Bag of Words (BoW) technique
- Bag of Words (BoW) and Trading
- Stepwise examples of using Bag of Words with Python
- Advantages of using Bag of Words
- Limitations of using Bag of Words
- Tips while using Bag of Words
- Real world applications of BOW in trading
- Stepwise examples of using Bag of Words with Python
Let us go through a quick introduction to Bag of Words starting with the brief overview of NLP.
Brief overview of Natural Language Processing
Natural Language Processing (NLP) is the bridge that connects the language we speak and write with the understanding of the language by machines. It's the technology behind chatbots, language translation apps, and even virtual assistants like Siri or Alexa. NLP enables computers to make sense of human language, making it a pivotal field in the age of information.
Importance of text analysis in NLP
Text analysis is the heartbeat of NLP. It's how we teach machines to read, comprehend, and derive meaning from the vast amount of text data (written in human language such as English) available online. From sentiment analysis of customer reviews to automatically categorising news articles, text analysis is the engine that powers NLP applications.
Introduction to the Bag of Words (BoW) technique
Now, let's get to the star of the show – the Bag of Words technique, often abbreviated as BoW. BoW is like the Lego bricks of NLP. It's a simple yet powerful method that allows us to convert chunks of text into manageable pieces that machines can work with.
With BoW, we break down sentences and paragraphs into individual words, then count how often each word appears. This creates a "bag" of words, ignoring grammar and word order but capturing the essence of the text. BoW forms the foundation for various NLP tasks, from sentiment analysis to topic modelling, and it's a great starting point for anyone venturing into the world of NLP.
Let us take a look at a simple example for understanding Bag of Words in depth.
Imagine taking a document, be it an article, a book, or even a tweet, and breaking it down into individual words. Then, we create a "bag" and toss those words in. This is the essence of the Bag of Words technique. BoW represents text data in a way that makes it computationally accessible. It's like creating a word inventory that machines can count and analyse, forming the basis for various NLP tasks.
So, let's dive in and explore the ins and outs of this versatile technique!
Bag of Words (BoW) and Trading
In the dynamic and information-driven world of trading and finance, staying ahead of market trends and making informed decisions is of paramount importance. To achieve this, professionals in the trading domain harness the power of text data analysis, and one valuable technique in their toolkit is the Bag of Words (BoW).
The Bag of Words approach is a text analysis method that extracts essential insights from textual sources such as financial news articles, social media discussions, and regulatory documents.
The Bag of Words (BoW) technique can be used in various aspects of the trading domain to analyse text data and extract valuable insights. Here are several specific applications of BoW in the trading domain:
- Sentiment Analysis: In trading, BoW can be used to perform sentiment analysis on various sources of text data, such as financial news articles, social media posts, and forum discussions. By analysing sentiment, traders and investors can gain insights into market sentiment trends, helping them make more informed decisions.
- Market News Summarisation: BoW can be applied to summarise and categorise financial news articles efficiently. This summarisation process enables traders and investors to quickly access key information about market trends, mergers and acquisitions, earnings reports, and economic indicators.
- Stock Prediction: BoW can be integrated into stock price prediction models as a feature extraction technique. By incorporating sentiment features derived from news articles and social media, traders can enhance their predictive models, potentially improving their ability to forecast stock price movements.
- Trading Signal Generation: Traders can use BoW to generate trading signals based on sentiment analysis. Positive sentiment in news or social media discussions may trigger buy signals, while negative sentiment may lead to sell signals, aiding in trading decisions.
- Risk Assessment: BoW can assist in assessing and quantifying the risk associated with specific assets or markets. It helps identify and categorise potential risks mentioned in news articles or analyst reports, contributing to better risk management strategies.
- Earnings Call Analysis: BoW can be applied to transcripts of earnings calls conducted by publicly traded companies. Analysing the sentiment expressed by company executives during these calls can provide valuable insights into future financial performance and market expectations.
- Regulatory Compliance: BoW can help financial institutions monitor and analyse regulatory compliance documents effectively. It aids in ensuring that companies adhere to relevant financial laws and regulations.
- Event-Based Trading: Traders can use BoW to detect and respond to significant events in real-time. For instance, the announcement of a merger or acquisition can trigger trading strategies based on news sentiment, allowing for timely market participation.
- Market Commentary Generation: BoW can be leveraged to automatically generate market commentaries and reports. It assists in summarising market conditions, trends, and news for traders and investors, providing them with concise and up-to-date information.
- Customer Feedback Analysis: In the trading domain, BoW can analyse customer feedback and comments on trading platforms or brokerage services. This analysis helps in understanding customer sentiment and can lead to improvements in user experiences and services.
- Risk Management: BoW can be a valuable tool in risk management by analysing textual reports and news for potential risks that may impact portfolios or trading strategies. It aids in identifying and mitigating risks effectively.
- Algorithmic Trading: BoW can be integrated into algorithmic trading strategies as a component for decision-making. Algorithms can consider sentiment signals derived from news and social media when executing trades, potentially enhancing trading performance.
Stepwise examples of using Bag of Words with Python
Now, let us see how to use Bag of Words step by step with the help of Python code. First of all, we will see a general example and then we will see an example to showcase using BOW in the trading domain.
Example 1: A General example
Here is a general example of BOW to give you an overview of the same.
Step 1: Import the CountVectorizer class from scikit-learn
In the first step, you import the CountVectorizer class from scikit-learn, which is a tool for converting text data into a numerical format suitable for machine learning model to read.
Step 2: Define a list of sample documents
You create a list called documents, which contains four sample text documents. These documents will be used to demonstrate the Bag of Words (BoW) technique.
Step 3: Create a CountVectorizer object
Here, you create an instance of the CountVectorizer class. This object will be used to transform the text data into a BoW matrix.
Step 4: Fit the vectorizer to the documents and transform them into a BoW matrix
This line of code fits the vectorizer to the documents and transforms the text data into a BoW matrix represented by the variable X. Here, each row in this matrix corresponds to a “document”, and each column corresponds to a “unique word” in the vocabulary.
Step 5: Get the vocabulary (unique words) and the BoW matrix
After transforming the documents, you extract the unique words (vocabulary) using vectorizer.get_feature_names_out(). The BoW matrix is stored in bow_matrix as a NumPy array.
Step 6: Display the vocabulary and the BoW matrix
Finally, you print the vocabulary (list of unique words) and the BoW matrix to the console, allowing you to see how the text data has been converted into a numerical representation.
Output:
Vocabulary (Unique Words):
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
Bag of Words Matrix:
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 1]
[1 0 0 1 1 0 1 1 1]
[0 1 1 1 0 0 1 0 1]]
The resulting “Bag of Words Matrix” represents the frequency of each word in each document. Each row corresponds to a document, and each column corresponds to a word from the vocabulary. The values in the matrix represent word counts.
The output is a Bag of Words (BoW) matrix generated from a set of documents. Let's break down the explanation of this specific BoW matrix:
- Each row in the matrix corresponds to a different document from the dataset. There are four rows, meaning there are four documents in this example.
- Each column represents a unique word (or term) found in the vocabulary of the documents. The vocabulary is determined by all the unique words present in the documents. In this case, there are nine unique words.
- The values in the matrix indicate how many times each unique word appears in each document. The numbers represent word frequencies within the respective documents.
Now, let's analyse the matrix itself below.
First Row:
- The first row corresponds to the first document in this dataset.
- It shows the word frequencies for each of the nine unique words.
- Hence, in this document, the word in the second column appears once, the word in the third column appears once, and so on.
For example:
- This document contains the words 'document,' 'first,' 'is,' 'the,' and 'this.' The word 'document' appears once, 'first' appears once, 'is' appears once, 'the' appears once, and 'this' appears once.
- The other words from the vocabulary do not appear in this document.
- So, it appears as follows:
[0 1 1 1 0 0 1 0 1]
Second Row:
- The second row corresponds to the second document.
- It shows word frequencies in this document for the same set of unique words.
- Therefore, the word in the second column appears twice, the word in the fourth column appears once, and so on.
For example:
- In the second document, we see the words 'and,' 'document,' 'is,' 'the,' 'second,' and 'this.'
- 'Document' appears twice, 'is' appears once, 'the' appears once, 'second' appears once, and 'this' appears once.
- The rest of the words from the vocabulary do not appear in this document.
- As a result, the row appears like this:
[0 2 0 1 0 1 1 0 1]
Third Row:
- The third row represents the third document.
- It shows how many times each unique word appears in this document.
- The word in the first column appears once, the word in the fourth column appears once, and so on.
For example:
- The third document contains the words 'and,' 'document,' 'is,' 'one,' 'the,' 'third,' and 'this.'
- 'And' appears once, 'document' appears once, 'is' appears once, 'one' appears once, 'the' appears once, 'third' appears once, and 'this' appears once.
- This results in the following row:
[1 0 0 1 1 0 1 1 1]
Fourth Row:
- The fourth row corresponds to the fourth document.
- It displays word frequencies within this document for the same set of unique words.
- The word in the second column appears once, the word in the third column appears once, and so on.
For example:
- In the fourth document, we observe the words 'document,' 'first,' 'is,' 'the,' and 'this.'
- 'Document' appears once, 'first' appears once, 'is' appears once, 'the' appears once, and 'this' appears once.
- The other words from the vocabulary do not appear in this document.
- This results in the following row:
[0 1 1 1 0 0 1 0 1]
Summary
Overall, this BoW matrix is a numerical representation of the documents, where each document is represented as a row, and the word frequencies are captured in the columns. It's a common way to preprocess text data for various natural language processing (NLP) tasks, such as text classification or sentiment analysis.
The code above demonstrates how the CountVectorizer in scikit-learn can be used to perform BoW analysis on a set of sample documents, making it easier to work with text data in machine learning tasks.
Example 2: How to use BOW in trading domain?
Now that you have a fair understanding of how to use Bag of Words, let us move to an example of the same in the trading domain. We are using Bag of Words to do sentiment analysis on the stock, that is, Apple Inc. in this case.
Step 1: Import necessary libraries and download NLTK resources
The code begins by importing the necessary libraries, including NLTK, yfinance, pandas, and related resources.
The script downloads essential NLTK resources, such as tokenizers, stopwords, and the VADER sentiment lexicon, using the nltk.download function.
Step 2: Provide text data, preprocess data and perform sentiment analysis
A list of text data is provided to the machine. The machine learning model uses this labeled data to learn patterns and relationships between text and sentiment. The model can then be used to make predictions on new, unlabelled text.
You must gather text data related to trading or financial news from sources such as news websites, financial forums, social media, or trading platforms. Ensure that the data is relevant to the trading domain.
These text snippets contain short sentences or phrases related to a stock and its products. In this case, it is Apple Inc. The purpose is to perform sentiment analysis on these texts.
The sample text data is preprocessed using the preprocess_text function. This involves cleaning and transforming the text data into a suitable format for analysis.
The code defines a function called analyze_sentiment, which conducts sentiment analysis on the input text. It uses NLTK's VADER sentiment analyser to calculate sentiment scores and determine whether the sentiment is positive, negative, or neutral.
In this example we are using the sample text data, which is as follows:
Now, preprocessing the data and performing of sentiment analysis will take place.
Step 3: Create a Bag of Words (BoW) matrix using CountVectorizer from scikit-learn
To analyse the text data quantitatively, a Bag of Words (BoW) matrix is created using the CountVectorizer from scikit-learn. This matrix represents the frequency of words in the preprocessed text data.
Also, we will convert matrix into dataframe.
Step 4: Calculate the sentiment score and store it into dataframe
For each text snippet in the sample data, sentiment scores are calculated using the analyze_sentiment function. The sentiment scores include a compound score that represents the overall sentiment of the text.
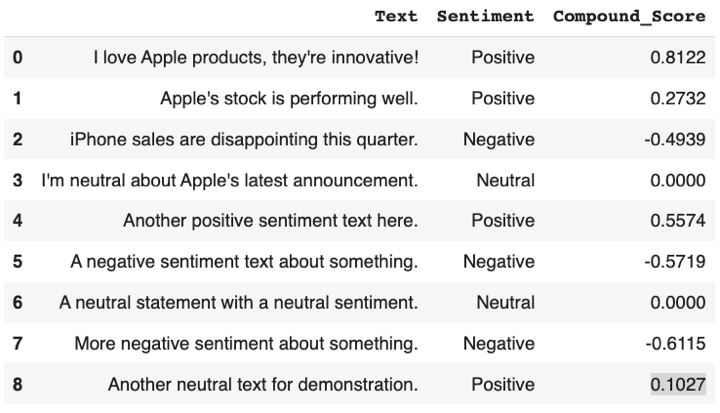
A pandas DataFrame named sentiment_df is created to store information about the sentiment of each text snippet. It includes columns for the original text, sentiment labels (positive, negative, or neutral), and compound sentiment scores.
Output:
Step 6: Visualise the sentiment analysis result
Output:
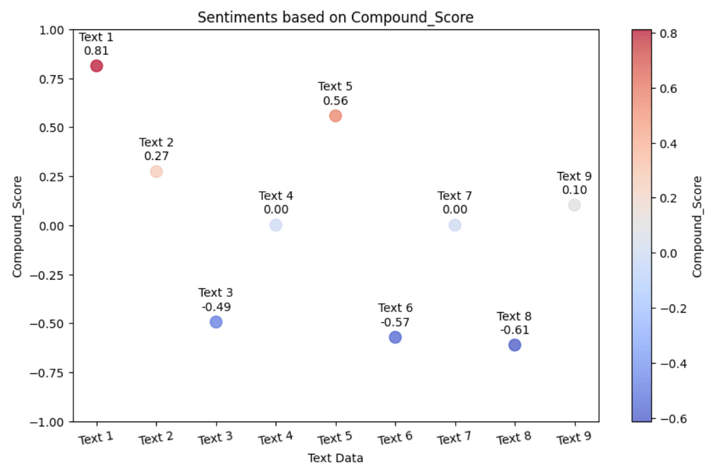
The colours in the scatter plot are used to distinguish between the sentiment categories. You can see that:
- Texts with a positive sentiment typically have a positive compound score (close to +1) and the data points are shown on the plots accordingly, visible as red coloured points and also in the lighter shade of red (or pink) wherever the score is lesser than 1. You can see that Text 9 is in between the neutral data point and positive data point and thus, is light in colour resembling white with a tinge of blue.
- Texts with a negative sentiment typically have a negative compound score (close to -1) and they are blue coloured points.
- As the texts go towards the neutral sentiment, having the compound scores close to zero indicate a lack of strong positive or negative sentiment. These data points are of light blue colour.
By using different colours for each sentiment category, you can visually identify the sentiment of each text at a glance when viewing the scatter plot.
Note: Always consider additional factors such as risk management, transaction costs, and position sizing to develop a more comprehensive trading strategy. Trading involves significant risks, and it's essential to do thorough research and testing before implementing any trading strategy.
Advantages of using Bag of Words
Now, let us see the advantages of using Bag of Words below.
- Simplicity: BoW is a straightforward and easy-to-implement technique for text analysis, making it accessible to users with various levels of expertise in natural language processing (NLP).
- Efficiency: BoW is computationally efficient and scales well to large datasets, making it suitable for processing large volumes of text data quickly.
- Feature Extraction: BoW effectively converts text data into a numerical format, which can be used as input for various machine learning algorithms. It helps in transforming unstructured text into structured data.
- Versatility: BoW can be applied to a wide range of NLP tasks, including text classification, sentiment analysis, document retrieval, and information retrieval.
- Interpretability: BoW representations are interpretable, allowing users to understand which words or terms contribute to the analysis and decision-making process.
Limitations of using Bag of Words
Below you can see the limitations of using Bag of Words.
- Loss of Sequence Information: BoW ignores the order of words in a document, leading to a loss of valuable sequential information. This can be problematic for tasks that depend on word order, such as language modelling or certain types of sentiment analysis.
- Sparse Representations: BoW matrices can be very sparse, especially when dealing with large vocabularies or documents. This can lead to high-dimensional data, which may require significant memory and computational resources.
- Lack of Context: BoW treats each word as independent, disregarding the context in which words appear. This can result in a loss of meaning and context in the analysis.
- Equal Importance: BoW assigns equal importance to all words, regardless of their relevance or importance in a specific task. Some words may be common but carry little informational value.
- Out-of-Vocabulary Words: BoW struggles with out-of-vocabulary words, as it cannot represent words that were not seen during the training phase, which may limit its effectiveness in handling new or rare terms.
Tips while using Bag of Words
With these tips below, you'll be directing a successful performance with Bag of Words, making it a valuable tool in your text analysis repertoire.
- Text Cleanup: Before the show, make sure to clean up the text with tokenisation, removing punctuation, and dealing with stop words. It's like dressing up for the occasion.
- Pick and Choose: Consider using TF-IDF (Term Frequency-Inverse Document Frequency) to let important words shine and dim the spotlight on common words.
- Size Matters: Be mindful of your vocabulary size. If it's too large, you'll have a stage that's too crowded. Prune it down to the essentials.
- Word Play: Sometimes, word embeddings like Word2Vec or GloVe steal the show. They capture word meanings and relationships better than traditional BoW.
- Customised Acts: Tailor your BoW approach to your specific NLP task. For sentiment analysis, focus on sentiment-related words.
- Curtain Call: Always evaluate how well your BoW-based models perform. It's like reviewing a play's performance to see if it wowed the audience.
Real world applications of BOW in trading
In the trading world, BoW acts as a valuable tool for extracting insights from textual data sources, enabling traders to make data-driven decisions, assess market sentiment, and manage risk effectively. It's a key component in leveraging unstructured data for informed trading strategies.
Let us now see some of the real-world applications of Bag of Words.
- News Sentiment Analysis: Traders use BoW to analyse news articles and financial reports. By extracting keywords and their frequencies from these texts, BoW helps assess market sentiment. Positive or negative sentiment can influence trading decisions, especially for short-term traders.
- Earnings Reports Analysis: When companies release earnings reports, BoW is used to scan the accompanying narratives. Traders look for keywords related to profit, revenue, guidance, and other financial metrics to make informed decisions about buying or selling stocks.
- Social Media Sentiment: Social media platforms are rich sources of market chatter. BoW is applied to social media feeds and forums to gauge sentiment regarding specific stocks or the market in general. It can help traders anticipate market movements based on public sentiment.
- Text-Based Trading Signals: Some trading algorithms incorporate BoW-generated trading signals. For instance, if there's a surge in negative news articles related to a particular stock, it might trigger a sell signal, while positive news may trigger a buy signal.
- Text Classification: BoW aids in categorising financial news and reports into relevant topics or classes. Traders can use this classification to filter information and focus on news that directly impacts their trading strategies. For instance, classifying news as "earnings reports," "macroeconomic indicators," or "regulatory changes" can help traders prioritise their research efforts.
- Risk Assessment: BoW is employed to identify and quantify risk factors in financial texts. It can help traders and risk managers spot potential risks in news articles or reports, such as mentions of bankruptcy, legal issues, or economic downturns. By quantifying these risks, traders can adjust their portfolios accordingly.
Conclusion
We've explored the Bag of Words (BoW) technique in Natural Language Processing (NLP). BoW simplifies text data by counting word frequencies, making it computationally accessible. We've covered its implementation in Python, from text preprocessing to visualisation.
BoW is efficient but lacks word order context. In trading, BoW aids in sentiment analysis, earnings reports, and social media monitoring. With this understanding, you're ready to leverage BoW for text analysis in various applications, including the dynamic world of trading.
To explore more about NLP and Bag of Words, refer to Natural language processing with python course by Quantra. With this course, you will be able to implement and compare the other word embedding methods with Bag of Words (BoW) such as TF-IDF, Word2Vec and BERT. If you are looking to trade based on the sentiments and opinions expressed in the news headline through cutting edge natural language processing techniques, then this is the right course for you.
File in the download:
Bag of Words - Python Notebook
Note: The original post has been revamped on 23rd November 2023 for accuracy, and recentness.
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.
