
By Mario Pisa
Social media and Twitter in particular are alternative data sources that are being used extensively to take the pulse of market sentiment.
In this post we will review the Tweepy library for fetching real-time and historical data from Twitter. We will go through the following topics:
- Twitter and Sentiment Analysis
- The impact of social networks on market trends
- What is Twitter?
- A Python Twitter API, tweepy
- How to install and set up Tweepy?
- Authentication on Twitter API
- How to use Tweepy to get tweets
- Tweets pagination with cursors
- Building a naive sentiment indicator
Twitter and Sentiment Analysis
Social networks and Twitter in particular are alternative data sources that are being used extensively as a market sentiment indicator.
Sentiment analysis of news and social networks is a comprehensive area of study where natural language processing is of vital importance to extract quantitative information from unstructured information sources.
We would need a book, if not an encyclopedia to describe the whole process of sentiment analysis and integrate it into our trading system.
So, in this post we are going to start with the first step, extracting information from Twitter to feed our Natural Language Processing algorithms.
Suggested reads:
- Blogs on Sentiment Trading
- Step By Step Guide To Natural Language Processing (NLP) In Trading
- How to Get Historical Market Data Through Python API
- Combining Sentiments in Trading and Business: How Hugo Explored Opportunities
The impact of social networks on market trends
Social networks have emerged as - mainstream communication media where users can be both consumers and creators of information.
Users are continuously generating data, either passively as mere receivers of information where our interest, reading time, etc. are recorded, or actively by creating content, expressing our interest in another content or even sharing it.
In addition, sufficiently interesting or shocking news can literally travel the world and become a global trend. Users with millions of followers can also create trends or impacts on specific topics.
The analysis of this type of data has been the subject of study for several years, having generated abundant academic material to model the flow of information, their interpretation and the extraction of mood, trends and forecasts.
What’s Twitter?
Twitter is a microblogging social network where users interact by posting information, sharing through retweets or showing their interest by marking information as a favourite.
It also has a hashtags (#) mechanism to tag content with the ability for the message to reach many more people than just followers.
According to the Internet Live Stats, Twitter has more than 372 million active users, and the number is continuously increasing, and more than 700 million tweets are posted every day.
There are users with millions of followers whose tweets can have a huge impact on markets. The cases of Donald Trump and Elon Musk are well known, where a single tweet can create shocks or booms.
On the other hand, hundreds of users can generate heated debates about a company, which creates trends about the mood of the investors. Debates with thousands, if not millions of passive and active viewers.
Twitter has therefore become a relevant source of alternative information for analysts who believe that social media sentiment can increase their edge in the markets.
A Python Twitter API, Tweepy
Tweepy is an easy-to-use Python library for accessing the Twitter API, as its - website claims. It’s not a unique library to connect to the Twitter API, but it is one of the best known and with very active development on GitHub.
As can be easily deduced from the previous paragraph, Tweepy allows us to connect to Twitter information to extract historical and real-time data. This means that we have tons of information available for analysis through this library.
The information from social networks, and Twitter in particular, is unstructured data and uses a lot of jargon, slang, emoticons, etc., which makes it especially complicated to analyze.
Natural Language Processing or NLP is an area specialized in extracting quantitative and qualitative information from all this unstructured information. When it is used in conjunction with classical statistical tools or machine learning, we are able to do sentiment analysis of social networks and unstructured data in general.
In one post there is not enough space to do a complete coverage of sentiment analysis in social networks, so here we are going to focus on the first but not least important step of sentiment analysis which is the extraction, transformation and loading of Twitter information into analysis’ algorithms.
How to install and set up Tweepy?
Install the Tweepy Python library as usual through the pip installer:
pip install tweepyOr clone the source code from GitHub and install it as a developer in your machine if you plan to modify the code and make your own contribution to the community.
git clone https://github.com/tweepy/tweepy.git cd tweepy python setup.py develop
In addition to installing the Tweepy library in Python, it is required to create a developer account on Twitter in order to obtain the keys that will allow us to connect with the Twitter servers to extract data.
Once the library is installed and the developer keys are obtained, we are ready to start working with information from Twitter.
Authentication on Twitter API
Start a terminal (Anaconda prompt if you want) and launch an interactive python session with the ipython command, import the tweepy library and assign variables for the keys.
Next we must create an authentication handler object and finally, create a tweepy object with the authentication handler object.


Now we have an object called api which is a socket connected against Twitter machines and enables us to extract tweets from specific users, extract tweets related to some word or set of words or even manage our own Twitter account.
How to use Tweepy to get tweets
The object api we have created allows us to use 105 RESTful methods from the Twitter API, some of them are only available for the premium API.
We can list all the available methods:

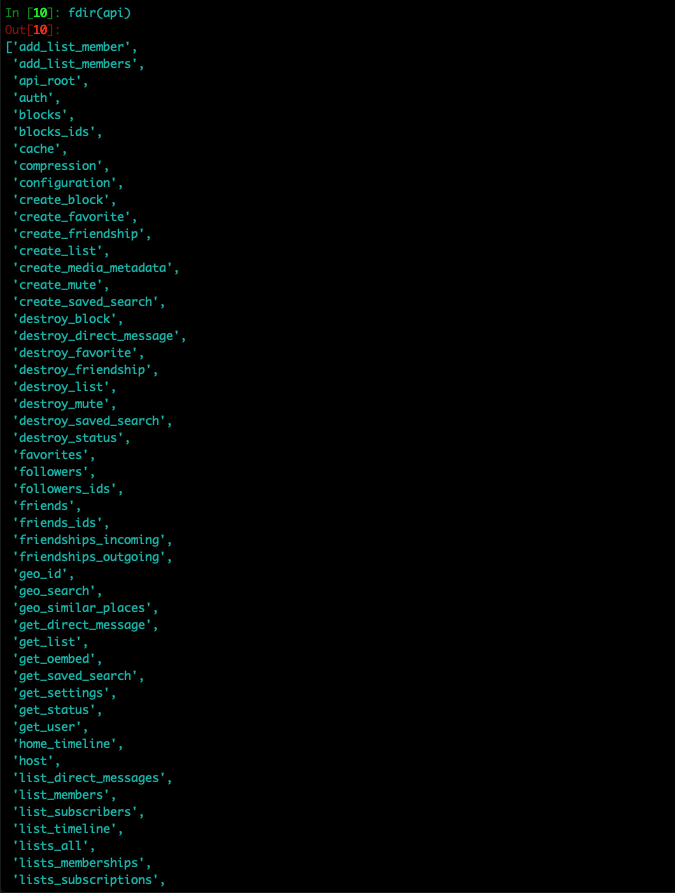
The list is not complete, although we have seen that we have 105 methods available. If we take a look, we will see that we can perform more functions than with the App itself and we can automate our own Twitter account and manage our publications or even create a completely autonomous bot to manage an account.
Some of the most used methods to get data are the following:
- search to search for tweets containing certain words
- user_timeline to search for tweets from specific users
search
Let’s get some tweets by looking for a word. We call the search method of the api object with the input parameter q for query.

Checking the results, we are getting a model (another object) with the tweets for the requested query, we get 15 tweets looking for the ticker of Johnson & Johnson $JNJ

Although this is the default number, we can increase it to 100 using the count input parameter, the maximum per request for a free Twitter API developer.

It is incredible the vast amount of meta-information that comes with a simple tweet of 140 characters, I have only included the first part of the result because to show it completely would require several pages.

So let's take a look at more specific information such as the date and time of the tweet, the user and the content posted.



Again, for the user it returns a large amount of metadata associated with the user, such as name, alias, number of followers, etc.
To see a little more detail, we need again to use the methods available in the search object.

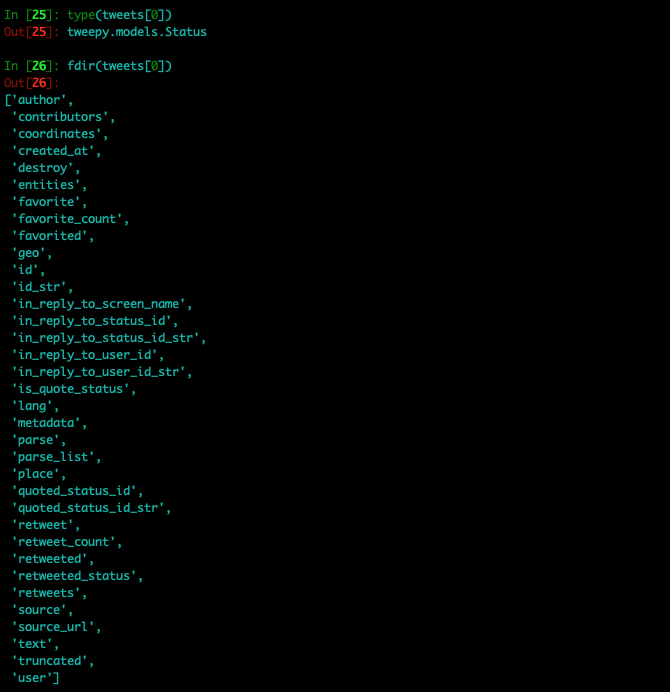
Remember that what Twitter returns us is an object model and as such, we have at our disposal countless methods to work with those objects.
Each tweet is an object of the Status class and we can see its methods here.
For the User model we have 52 methods available for working with users.

Please, check the documentation to learn about the large number of parameters that can be used in searches.
user_timeline
Another of the most used methods of the Twitter API is the user_timeline that allows us to analyze all the publications of a particular user.
Elon Musk's account is hot, he has millions of followers and some of his posts cause seismic movements. Let's pull down some of his tweets.

Again we can see that what we get is an object of class ResultSet or properly speaking a model of objects that provide us with a multitude of methods to work with the information.


Note that the maximum number of tweets returned is 20 by default, although we can extend it up to 200 with the count parameter.

It is not possible here to describe each of the parameters for the user_timeline function so we strongly recommend you to visit the Tweepy documentation.
Tweets pagination with cursors
When we need large amounts of data we will continually need the use of cursors. Cursors is an API method for creating iterable objects and working with blocks of information.
The cursor object has two main methods, pages to deal with blocks of information or tweets and the items to deal with individual tweets.

The cursor is initialized with a model, for example search or user_timeline and it returns an iterable object.


As we can see, we get much more tweets than using the user_timeline in this case that was limited to 200. With the cursor we are fetching up to 950 tweets for this example as we can see below:
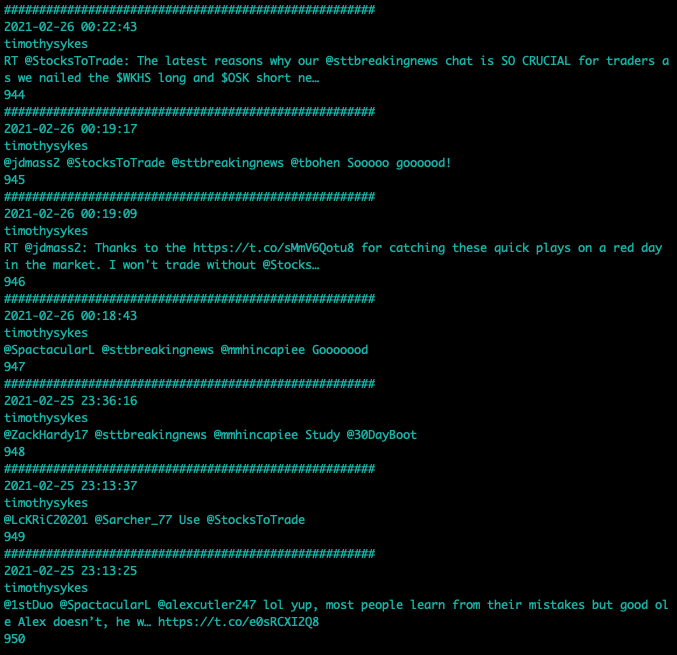
Cursors are very interesting to filter by date range, users, words, hashtags and so on.
What we have seen so far enables us to work with historical information from Twitter. We will now see how to work with real-time information.
Real time tweets
To retrieve Twitter messages in real time or, in other words, a more or less a continuous stream of tweets (depending on the filter used), we need to create a listener.
Unlike the objects we have been reviewing, which offered us a series of methods through a RESTful interface to send requests, the listener opens a socket and through Push technology we receive the messages.
This may sound a bit exotic, but actually all the hard work is done by the Tweepy library and we only have to create the appropriate object.
The only thing we have to do is to create a class that inherits from the StreamListener class and here we can overwrite the methods we are interested in. Again it is recommended to check the official documentation to see the available methods.

After a moment, we will start to see the stream of tweets that are arriving based on the filter we have defined.

The image is truncated. Unless we stop the execution, every time a new tweet meets out filter criteria, the on_data method is magically executed.
Note there are several methods starting with on_* that are automatically executed based on different criteria such as on_status, on_error, and so on.
Building a sentiment indicator
To build a sentiment indicator with the information flowing through Twitter it is necessary to understand the information contained in the tweets. We can search by tickers such as $AMZN but we need to find out the sentiment of the person who is posting it, by interpreting positive or negative words and sentences.
To help us with text interpretation there are other natural language processing libraries that will help us to quantify and qualify the text we are receiving such as NLTK or VADER.
Indeed, we will need a chain of models to obtain a quantified interpretation of the information content in order to interpret the sentiment of the tweets.
Suggested reads
Conclusion
We have seen how the Tweepy library makes it easy to establish a connection with Twitter to extract information from users or tweets.
The access to historical information can be done using the RESTful methods that Twitter provides us to get data from tweets that contain certain words, get tweets from specific users, hashtags, etc.
In order to gather real-time information from Twitter, the methods inherited from the StreamListener class are overwritten so that the tweets can be sent through Push technology based on the filter we have.
With Tweepy we can get a lot of information from Twitter but as we have seen, it is only the first step in a sentiment analysis. The next step is to learn how to handle natural language processing libraries.
Want to harness alternate sources of data, to quantify human sentiments expressed in news and tweets using machine learning techniques? Check out this course on Trading Strategies with News and Tweets. You can use sentiment indicators and sentiment scores to create trading strategy and implement the same in live trading.
References
- https://dev.twitter.com/docs
- https://docs.tweepy.org/en/latest/index.html
- https://quantra.quantinsti.com/course/trading-twitter-sentiment-analysis
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.

