
By Mario Pisa
Zipline is a fantastic tool for backtesting and data is the main raw material for doing this kind of analysis. In this post, we are going to focus on how to load our own data files. Through an example, we will create a bundle to load data from csv files downloaded from Yahoo finance.
We cover:
- Zipline recap
- A bundle overview
- Creating a bundle for Yahoo csv daily data
- Registering the bundle
- Ingesting data into Zipline
- Run a backtest with the new bundle
Zipline recap
As we saw in the last post, the Zipline library is a powerful tool for backtesting that lets us focus on the strategy not without first making every effort to have the system ready.
Although Quantopian has stopped operations, we can still enjoy the great work they did with the Zipline library.
In this blog, we will see how to load data in Zipline from several sources such as Yahoo. The data will come from csv files for undated instruments such as:
- Stocks,
- ETFs,
- CFDs,
- FX, etc.
Before reading on, it's imperative to remember that if you want to simplify your life, you can use Blueshift that provides historical data for backtesting and real-time data with connection to several brokers to put your algorithm live without the slightest effort. Otherwise, keep reading.
Zipline calls this the ingest process. The connector that lets us be able to read a data source and load to Zipline is the bundle script.
By default, the Zipline library comes with a few bundles to connect with eg. Quandl Python API Wiki DB and csv files. Yet usually we need to connect to other data sources with different formats, column names, etc.
For this reason, we need to create a bundle in order to be able to ingest the data and run backtests over them. That’s the topic we discuss here.
Suggested read: Introduction To Zipline In Python
A bundle overview
A bundle is an ETL tool. The Extraction, Transformation and Load (ETL) is a well-known process in data science. It means that the bundle Python script needs to connect to a data source (web, file or database).
- Extract the data and load into memory in a convenient data structure as a DataFrame.
- Normalize the data by cleaning and Transforming the NA, column names, dates and times, etc.
- Finally, load the normalized data into the Zipline data repository. By default is an SQLite although can be any other DB.
Although it may seem like an overwhelming task, we can use the available csvdir bundle as a template. So the bundle development will be a bit easier.
Creating a bundle for Yahoo csv daily data
Let's assume we have a folder with daily data downloaded from Yahoo. Note that, by default, the csvdir.py script looks for the data inside folders named daily and minute, hence we need to include Yahoo's csv files inside the daily folder.
The whole process in one line:
We need to read the data, transform them to the Zipline format and load them into the Zipline repository. This is the ETL process.
We will use the csvdir bundle included with the library as a template. The csvdir.py script is inside the following folder:
~/opt/miniconda3/envs/zipline35/lib/python3.5/site-packages/zipline/data/bundles
The marked part of the path depends on your machine and on the Conda environment name you are using. Our customized bundle file must be in that folder too.
First, let's create a copy of the csvdir.py to a recognizable name for what we are going to do. For example, here, we will make a bundle for Yahoo data listed on the NYSE. For example yahoo_NYSE.py
Open the new yahoo_NYSE.py bundle in your favourite editor. We are going to start editing it to adapt the Yahoo data to Zipline data format and be able to use it in the ingestion process.
If we look inside the file, we have functions, classes and methods needed to undertake in the ETL process. In this post we won't explain all the code, you have the API documentation for that. Here we'll look at the parts needed for understanding and change.
Change the name of the main function, I like to use the same name as the file name. So the name will be yahoo_NYSE.

This function accepts two input parameters. The first one is a list offor the data frequency. Minute, daily or both. The second one, is the folder where we have the Yahoo daily data for this case. We don't use these parameters at this point, but it is useful to be aware of them.
The output of this function is a class named CSVDIRBundle, modify this name as, for example, Yahoo_NYSEBundle.

At lines 92, 97 and 98 it’s needed to change the bundle name, this is the function name we call with the ingest zipline’s command. Line 97 indicates the name we will be registering as a bundle inside Zipline.
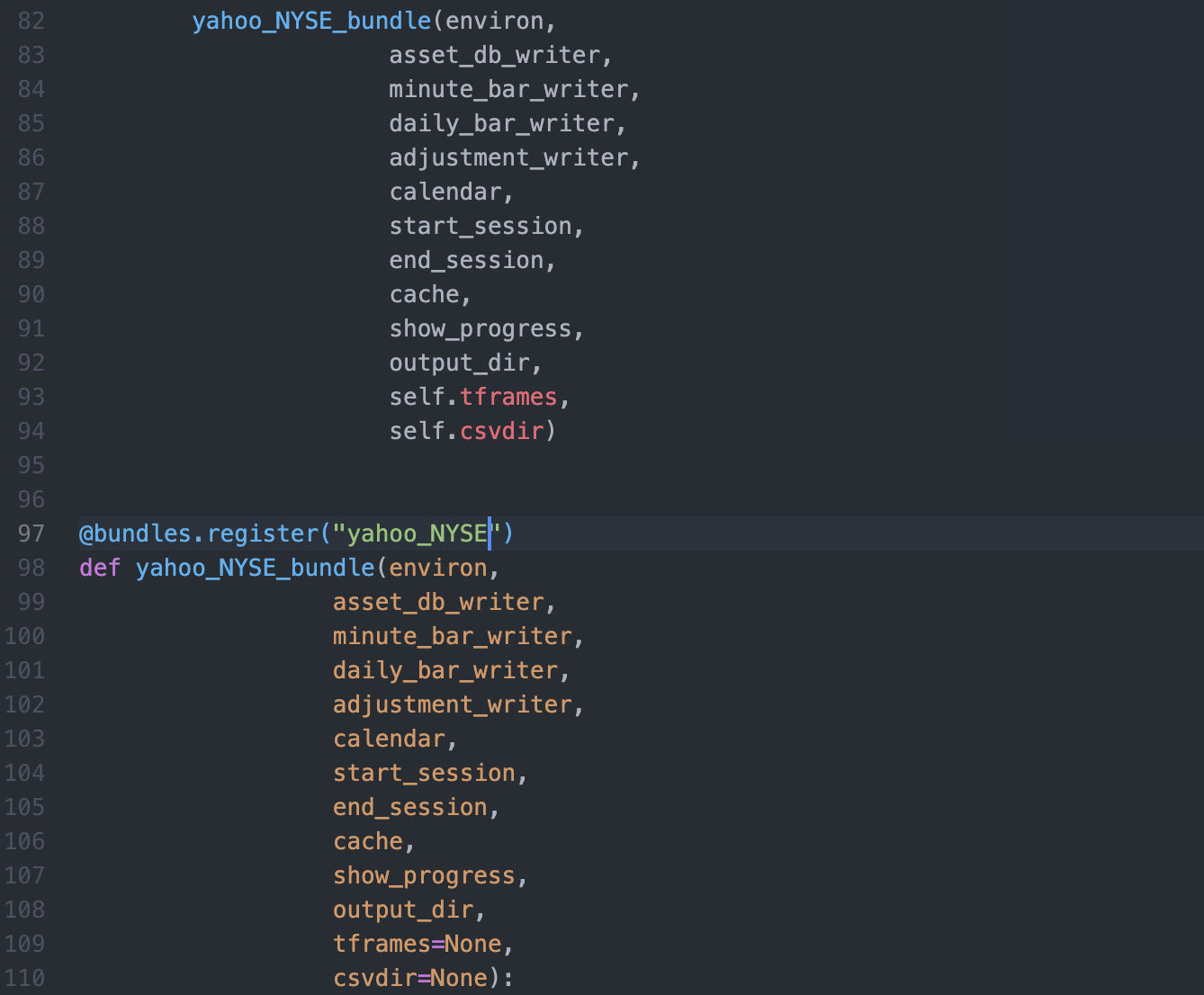
Inside the function declared at line 98, we can see the data format expected by Zipline, there is some code to deal with the input parameters and works with metadata, splits, etc.
We need to modify the market calendar CSVDIR in order to use the generic market calendar for the NYSE at line 161.

The function needed to modify in order to adapt our data into Zipline format is named _pricing_iter at line 171. This function reads the csv files and loads them into the Zipline DB.

Here we can see the key part of the code:

It reads the csv files and after that, we can inspect the content, modify the column names, drop the NA or any other change required in the data. For example, in line 188, we drop the possible duplicate dates.
We can include as many print sentences as needed to trace the code execution.
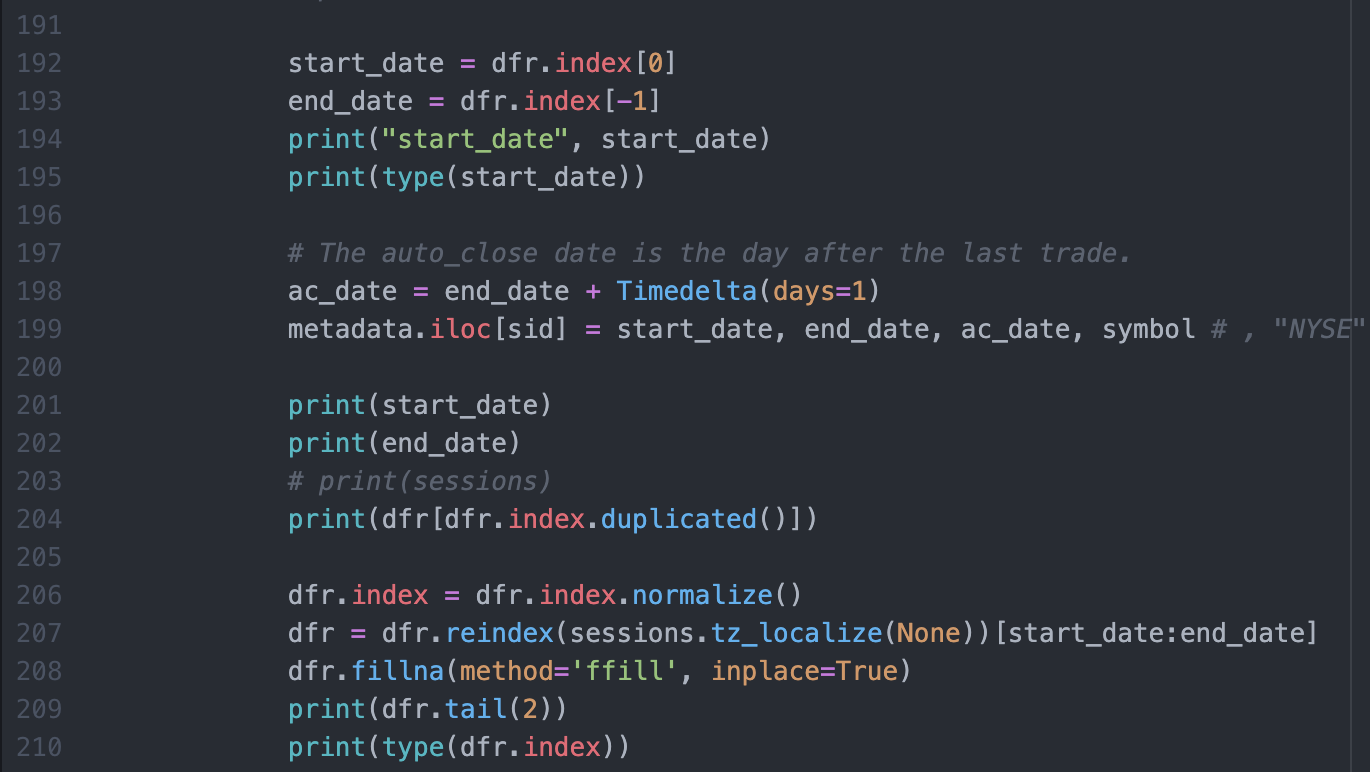
The key here is to align the csv data index with the NYSE market calendar. Line 207 needs the sessions variable to do that.
We create the sessions dates from our data first date to the last date. Include this line at line 154, after the time frame is defined.

Include the variable name in the parameters of the write function calling, line 156.

And accept it in the input parameters of the _pricing_iter function.

Finally, comment or drop the last code line, because we want to use the NYSE calendar with these data files.

Registering the bundle
The last step is to register our yahoo_nyse bundle. Open (if exists) or create (if not exists) the extension.py file and include the new bundle.
~/.zipline/extension.py

Look at the input parameters, tframes is a list and can be minute, daily or both, and the csvdir is the folder where the data files downloaded from Yahoo are. The data are inside the daily folder although this endpoint is not specified in the csvdir path.
Ingesting data into Zipline
Well, we are here, let’s test the new bundle ingesting some data from Yahoo stored on
~/DATA/Yahoo_NYSE/daily

If all is well, you will see all the print sentences that we have included in the code. If the process ends without errors, we have our data inside the Zipline DB.
Run a backtest with the new bundle
Let’s check the simple algorithm with our data.
Initialize the algorithm with an existing symbol:

The complete algorithm code can be downloaded at the end of this post and/or from the first post about installing Zipline.
In the results section, be sure you are using the new bundle yahoo_NYSE

Hopefully, things will go well and you will get a nice chart.
Suggested reads:
Conclusion
Here we can modify the csvdir.py file to get a tuned bundle for Yahoo NYSE daily data. We don’t care so much about the code. However, there are many lines that can be deleted in order to get a clean code.
To load minute data or load data from other providers is very similar. Just adapt the Pandas DataFrame to the Zipline format inside the _pricing_iter function.
In a future post, we will try to ingest online data to avoid the csv files.
Remember that, in order to simplify your life with Zipline and spend your time just thinking about strategies instead of the architecture, you can use Blueshift to backtest strategies and go live at any time.
Files in the download
- First Zipline Backtest python code
- Yahoo_NSE python code
- Extension python code
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.
