
By Chainika Thakar, Anupriya Gupta and Milind Paradkar
High Frequency Trading is a subset of algorithmic trading and is executed by high frequency trading algorithms. The heart or the core of HFT is a combination of: High-Speed Computer Systems & Real-Time Data Feed (which tracks trades and order book quickly).
By the end of this article, you will be well-equipped with useful knowledge concerning High Frequency Trading, High frequency trading algorithms, and more.
This article covers:
- What is High Frequency Trading?
- How does High Frequency Trading work?
- High Frequency Trading Orders
- History of High Frequency Trading
- Facts about High Frequency Trading
- Features of High Frequency Data
- High Frequency Trading Strategies
- Who uses High Frequency Trading?
- High Frequency Trading Jobs
- Top High Frequency Trading Firms in India
- Top High Frequency Trading Firms Globally
- Requirements for setting up a High Frequency Trading Desk
- Regulatory requirements for High Frequency Trading
- High Frequency Trading vs Long-term Investments
What is High Frequency Trading?
High Frequency Trading is a trading practice in the stock market for placing and executing many trade orders at an extremely high-speed. Technically speaking, High Frequency Trading uses HFT algorithms for analysing multiple markets and executing trade orders in the most profitable way. Start with our free stock market beginner course to build your foundational knowledge.
A High Frequency Trader uses advanced technological innovations to get information faster than anyone else in the market. With this information, the trader is able to execute the trading order at a rapid rate with his high frequency trading algorithms.
Co-location is the practice to facilitate access to such fast information and also to execute the trades quickly.
After all, with all your trading strategies and strong analysis in place, what else can there be remaining?
Well, the answer is High Frequency of Trading since it takes care of the Frequency at which the number of trades take place in a specific time interval. High Frequency is opted for because it facilitates trading at a high-speed and is one of the factors contributing to the maximisation of the gains for a trader.
How does High Frequency Trading work?
High Frequency Trading is mainly a game of latency (Tick-To-Trade), which basically means how fast does your strategy respond to the incoming market data.
The "Bleeding edge" firm actually talks of single-digit microsecond or even sub-microsecond level latency (Ultra High Frequency Trading) with newer, sophisticated and customized hardware.
Conclusively, in the past 20 years, the difference between what buyers want to pay and sellers want to be paid has fallen dramatically. One of the reasons for this is the increase in accuracy. HFT has also added more liquidity to the market, reducing bid-ask spreads.
High Frequency Trading Orders
High Frequency Trading includes four types of HFT Orders and we have discussed the same in the infographic below.
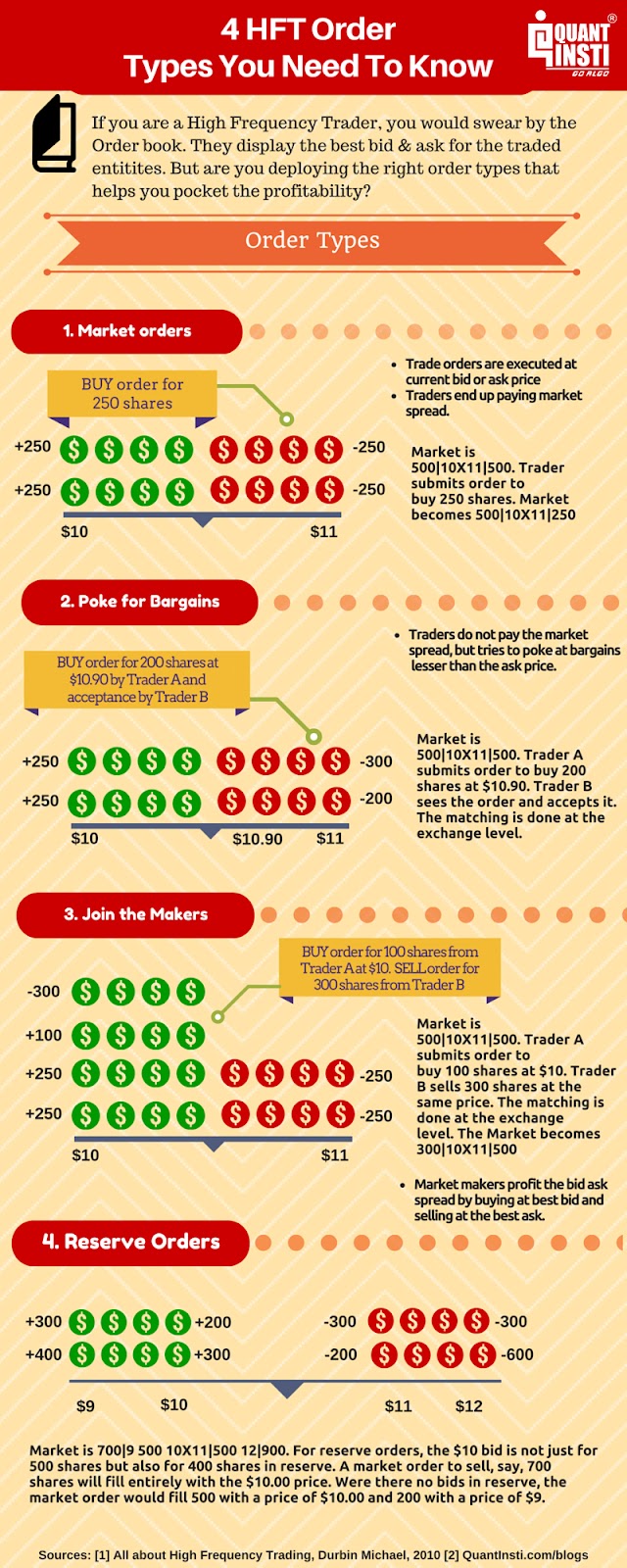
Moving forward, let us take a look at the History and Interesting Facts of HFT.
History of High Frequency Trading
Interestingly, the phenomenon of ‘fast information’ delivery goes back to the 17th century.
- 17th Century - Using technology, Nathan Mayer Rothschild knew about the victory of the Duke of Wellington over Napoleon at Waterloo before the government of London did.
- 19th Century - It is said that Julius Reuter, the founder of Thomson Reuters, in the 19th century used a combination of technology including telegraph cables and a fleet of carrier pigeons to run a news delivery system. This way, the information reached Julius Reuter much before anyone else.
- 1983 - NASDAQ introduced full-fledged electronic trading which prompted the computer-based High Frequency Trading to develop gradually into its advanced stage.
- 2000s - In the early 2000s HFT accounted for less than 10% of equity orders, but this has grown rapidly.
- 2001 - By the year 2001, HFT had an execution time of several seconds which kept improving further.
- 2005 to 2006 - Between 2005 and 2009, according to NYSE, high frequency trading volume grew by 164%.
- 2010 - By 2010, this had shrunk to milliseconds and later in the year went to microseconds.
- 2012 - And subsequently, each trade started getting executed within nanoseconds in 2012.
Facts about High Frequency Trading
Latency
Speed is not something which is given as much importance as is given to underpriced latency. Latency implies the time taken for the data to travel to its destination. Hence, an underpriced latency has become more important than low latency (or High-speed).
Speed
According to Bloomberg, Speed is still important, but it’s internal, not external. Traditional HFT meant a short time between an order coming to market and your ability to take it. It consisted mainly of external transmission delays, firms quickly learned to make their internal decision time so fast that it was insignificant to the outcome.
Decision making
Internal decision time goes into deciding the best trade so that the trade does not become worthless even after being the first one to pick the trade. Since High Frequency Trading is so unique with regard to many aspects, it is obvious that you would want to know what characteristics make it so.
Market making
High Frequency Trading firms characterize their business as "Market making”. Every market-maker functions by displaying buy and sell quotations for a specific number of securities. As soon as an order is received from a buyer, the Market Maker sells the shares from its own inventory and completes the order. Consequently, this process increases liquidity in the market. Hence, it is known as the Market Making Strategy.
Signals
The precision of signals (buy/sell signals) is paramount since gains may quickly turn to losses if signals are not transferred rightly. So, HFT makes sure that every signal is precise enough to trigger trades at such a high level of speed.
Tick By Tick Data
Market data changes trigger High Frequency Trading systems to produce new orders in a few hundred nanoseconds. Hence, the collected data can consist of billions of data rows!
Colocation
This implies locating computers owned by High Frequency Trading firms and proprietary traders in the same premises where an exchange's computer servers are housed. Hence, Co-location enables HFT firms with high-performing servers to get faster market access.
Asset Classes
High Frequency Trading Proprietary Firms trade in Stocks, Futures, Bonds, Options, FX, etc. HFT from anywhere and at any point in time, thus, making it a preferred option for FX trading.
High-End Systems
Just staying in the high-frequency game requires ongoing maintenance and upgrades to keep up with the demands. For this to happen, banks and other financial institutions invest fortunes on developing superfast computer hardware and execution engines in the world.
Skilled Pros
High Frequency Trading professionals are increasingly in demand and reap top-dollar compensation. The solid footing in both theory and practice of finance and computer science are the common prerequisites for the successful implementation of high-frequency environments.
Great! Going ahead, let us explore the Features of High-Frequency Data.
Features of High Frequency Data
As the race to zero latency continues, high-frequency data, a key component in HFT, remains under the scanner of researchers and quants across markets.
With some features/characteristics of High-Frequency data, it is much better an understanding with regard to the trading side. The data involved in HFT plays an important role just like the data involved in any type of trading.
With deep insight into the data of HFT, you will be able to understand the technical side of the working of High Frequency Trading. This section aims to unravel some of these features for our readers, and they are:
Irregular time intervals between observations
On any given trading day, liquid markets generate thousands of ticks which form the high-frequency data. By nature, this data is irregularly spaced in time and is humongous compared to the regularly spaced end-of-the-day (EOD) data.
HFT involves analyzing this data for formulating trading Strategies which are implemented with very low latencies. As such it becomes very essential for mathematical tools and models to incorporate the features of High-Frequency data such as irregular time series and some others that we will outline below to arrive at the right trading decisions.
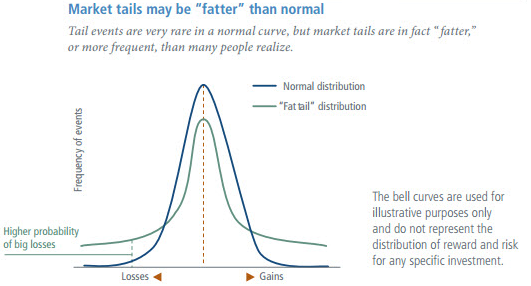
Non-normal asset return distributions (for example, fat tail distributions)
High-frequency data exhibit fat tail distributions. To understand fat tails we need to first understand a normal distribution. A normal distribution assumes that all values in a sample will be distributed equally above and below the mean.
Thus, about 99.7% of all values fall within three standard deviations of the mean and therefore there is only a 0.3% chance of an extreme event occurring.
Quant analysts doing HFT need to model the tail risks to avoid big losses, and hence tail risk hedging assumes importance in High Frequency Trading.
The plot shown below illustrates a fat tail distribution vis-à-vis normal distribution.
Further, High-frequency data exhibits:
- Volatility Clustering and
- Long-range dependence (Long Memory) in absolute values of returns.
Volatility Clustering
In finance, volatility clustering refers to the observation, as noted by Mandelbrot (1963), that "large changes tend to be followed by large changes, of either signs and small changes tend to be followed by small changes."
Long-range dependence (Long memory)
Long-range dependence (LRD), also called long memory or long-range persistence is a phenomenon that may arise in the analysis of spatial or time-series data. This relates to the rate of decay of statistical dependence of two points with increasing time interval or spatial distance between the points. It is a must to note that a phenomenon is usually considered to have long-range dependence if the dependence decays more slowly than an exponential decay, typically a power-like decay.
High computation load and related “Big data” (also, problems with it)
HFT players rely on microsecond/nanosecond latency and have to deal with enormous data. Utilizing big data for HFT comes with its own set of problems.
High Frequency Trading firms need to have the latest state-of-the-art hardware and latest software technology to deal with big data. Otherwise, it can increase the processing time beyond the acceptable standards.
Market Microstructure Noise
Market Microstructure Noise is a phenomenon observed with high-frequency data that relates to the observed deviation of the price from the base price. The presence of Noise makes high-frequency estimates of some parameters like realized volatility very unstable. Noise in high-frequency data can result from various factors namely:
- Bid-Ask Bounce
- Asymmetric information
- Discreteness of price changes
- Order arrival latency
Bid-Ask bounce
It occurs when the price for a stock keeps changing from the bid price to ask price (or vice versa). The stock price movement takes place only inside the bid-ask spread, which gives rise to the bounce effect. This occurrence of bid-ask bounce gives rise to high volatility readings even if the price stays within the bid-ask window.
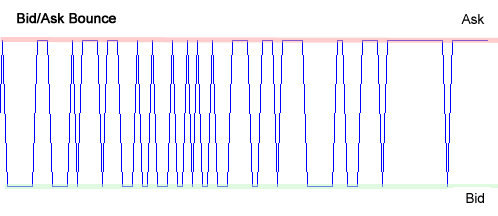
Asymmetric information
In the case of non-aligned information, it is difficult for high frequency traders to put the right estimate of stock prices.
Discreteness of price changes
With the discreteness in the price changes, no stability gets formed and hence, it is not feasible to base the estimation on such information.
Order arrival latency
Latency means the amount of time it takes for either an order to reach the stock market or for it to be executed further. In the case of High Order Arrival Latency, the trader can not base its order execution decisions at the time when it is most profitable to trade.
On the other hand, with a Low Order Arrival Latency, the order can reach the market at the most profitable moment.
Ahead, let us take a look at the interesting High Frequency Trading Strategies.
High Frequency Trading Strategies
HFT firms use different types of High Frequency Trading Strategies and the end objective as well as underlying philosophies of each vary. These Strategies are based on the analysis of the market, and thus, decide the success or failure of your trade.
Hence, it is important to put forth only the Strategy that suits you the best. Some of the important types of HFT Strategies are:
Order flow prediction High Frequency Trading Strategies
Order flow prediction Strategies try to predict the orders of large players in advance by various means. Then, they take trading positions ahead of them and lock in the profits as a result of subsequent price impact from trades of these large players.
Execution High Frequency Trading Strategies
Execution HFT Strategies seek to execute the large orders of various institutional players without causing a significant price impact. These include:
- VWAP (Volume-Weighted Average Price) Strategy – This Strategy is used to execute large orders at a better average price. It is the ratio of the value traded to the total volume traded over a time period.
- TWAP (Time-Weighted Average Price) Strategy – This Strategy is used for buying or selling large blocks of shares without affecting the price.
Before moving ahead lets take a moment for this quick tutorial of how VWAP and TWAP trading strategies works?
Liquidity Provisioning – Market Making Strategies
High Frequency Trading market-makers are required to first establish a quote and keep updating it continuously in response to other order submissions or cancellations. This continuous updating of the quote can be based on the type of the model followed by the High Frequency Trading Market-Maker. In the process, the HFT market-makers tend to submit and cancel a large number of orders for each transaction.
Automated High Frequency Trading Arbitrage Strategies
HFT Arbitrage Strategies try to capture small profits when a price differential results between two similar instruments. Index arbitrage can be considered as an example of the same. The price movement between the S&P 500 futures and SPY (an ETF that tracks the S&P 500 index) should move in line with each other. If you want to learn more, you can explore our futures trading course here.
If the price movement differs, then the index arbitrageurs would immediately try to capture profits through arbitrage using their automated HFT Strategies. To do it effectively, the High Frequency Trading Arbitrage Strategies require rapid execution, so as to quickly maximise their gains from the mispricing, before other participants jump in.
Apart from the ones discussed above, there are other High Frequency Trading Strategies like:
- Rebate Arbitrage Strategies which seek to earn the rebates offered by exchanges.
- HFT strategies based on Low latency news feeds.
- Iceberg and Sniffer which are used to detect and react to other traders trying to hide large block trades.
Who uses High Frequency Trading?
High Frequency Trading is used by the firms belonging to following categories:
- Independent Proprietary Firms - These firms tend to remain secretive about their operations and the majority of them act as market makers.
- Broker-Dealer Proprietary Desks - These traditional Broker-Dealer firms have separate desks for High Frequency Trading which are unrelated to their client businesses.
- Hedge Funds - Firms consisting of Hedge Funds put the emphasis on statistical arbitrage to take advantage of pricing inefficiencies amongst asset classes & securities.
Furthermore, in order to improvise upon your trading outcomes, we have an elaborative course “Advanced Algorithmic Trading Strategies”, which should help in case you are looking for something to enhance your trading experience.
Okay now! We will take a look at the career aspect in HFT firm ahead.
High Frequency Trading Jobs
There are some important roles you can choose from across the globe, once you become a qualified candidate. All the roles we will discuss here are quite significant and rewarding. Take a look at the list below, which includes:
- Quant Analyst / Model Developer
- Strategy Developer
- Trader
- Networks/System Administrator
Quant Analyst / Model Developer
If you are interested in building models yourself and want to apply for a quant analyst/ model developer role, pick up quantitative skills with working knowledge of using quant tools such as R, Matlab, Python.
Strategy Developer
For strategy developer role, you would be expected to either code strategies, or maintain and modify existing strategies. Most likely you would be working with a quant analyst who would have developed the trading model and you would be required to code the strategy into an execution platform.
Trader
For the trading role, your knowledge of finance would be crucial along with your problem-solving abilities. If you are good at puzzles and problem solving, you will enjoy the intricacies and complexities of the financial world.
Networks/System Administrator
Core development work which involves maintaining the high frequency trading platform and coding strategies are usually in C++ or JAVA. Hence, honing your C++ or core development language is definitely essential.
There are some HFT firms which generally focus on Arbitrage and Quantitative Strategies. The list of such firms is long enough, but these can serve your purpose of finding a job as a quant analyst or a quant developer in one of these.
We have shared details and how you can explore and learn about high frequency trading jobs in a separate blog.
Top High Frequency Trading Firms in India
- Tower Research (Gurgaon)
- Goldman Sachs (Bangalore/Mumbai)
- Morgan Stanley (Mumbai)
- iRageCapital (Mumbai)
- Estee Advisors (Gurgaon)
- Quadeye (Gurgaon)
- Acceletrade Technologies (Bangalore)
- Dolat Group (Mumbai)
- Edelweiss (Mumbai)
- APT (Gurgaon)
- Open Futures (Delhi)
- Graviton Research Capital LLP (Gurugram)
- Alphagrep Securities (Mumbai)
Top High Frequency Trading Firms Globally
- Citadel Securities (New York, U.S.A)
- Flow Traders NV (Amsterdam, Netherlands)
- GSA Capital Partners LLP (London, U.K)
- IMC Trading BV (Amsterdam, Netherlands)
- Jump Trading (Chicago, U.S.A)
- KCG Holdings Inc. (Hampton Roads, U.S.A)
- Virtu Financial Inc (New York, U.S.A)
Note: In case you are looking to develop a career in the quantitative trading domain, a high-frequency trading course like EPAT is the best suited algo trading course for you. EPAT offers the most comprehensive curriculum which is taught by leading industry practitioners and experts. Once completed, you get access to life-time career assistance.
Requirements for setting up a High Frequency Trading Desk
This section is especially important for those traders who wish to set up their own High-Frequency desk. Basically, you require a number of things we have listed down here, and they are:
Registering the Firm
First of all, you need to register the firm you wish to trade under. This can be done in two ways: in Partnership OR as an Individual. It is important to note that you may need approvals from the regulatory authority in case you wish to set up a Hedge Fund with other investors.
Capital for Trading & Operations
Capital in HFT firms is a must for carrying out trading and operations. This helps you arrange everything you need from basic network equipment like Routers/Modems and Switches to co-location of your system.
Access to Market
If you don’t want to go for direct membership with the exchange, you can also go through a broker. This involves lesser compliance rules and regulatory requirements. However, the flip-side is that you will have to pay brokerage.
Infrastructure Requirements
For infrastructure, you will be mainly needing:
- Hardware - implies the Computing hardware for carrying out operations. This is nothing but your computing system.
- Network Equipment - implies your Routers/Modems, Switches, Internet and so on.
Audit & Compliance
All HFT firms in India have to undergo a half-yearly audit. Auditing can only be done by certified auditors listed on the exchange’s (for instance NYSE for the US) website. For audit, you are required to maintain records like order logs, trade logs, control parameters etc. of the past few years.
Moving ahead, we will discuss the Regulatory Requirements in HFT.
Regulatory requirements for High Frequency Trading
Around the world, a number of laws have been implemented to discourage activities which may be detrimental to financial markets. Some experts have been arguing that some of the regulations targeted at HFT activities would not be beneficial to the market.
They have stated that on one hand, we have high frequency traders acting as market makers who have order-flow driven information and speed advantages. On the other hand, we have traders who are not sensitive to the latency as such.
Empirical results, in general, suggest that these regulations targeted towards HFT do not necessarily improve market quality. It is so since they fail to offer sufficient evidence pertaining to sudden market failures such as the Flash Crash.
Some regulatory changes in High Frequency Trading are:
Financial Transaction Taxes
FTT is used to limit HFT related excessive trading. Also, this practice leads to an increase in revenue for the government. At the right level, FTT could pare back High Frequency Trading without undermining other types of trading, including other forms of very rapid, high-speed trading.
Let us take the examples of a few countries with regard to FTT.
EU FTT - According to europarl, On 14th February 2013, the Commission of EU proposed to introduce FTT in the eleven member states but with the instrument of ‘enhanced cooperation’.
But on 25th March 2015, Parliament realised and regretted that the member states did not exercise their enhanced cooperation. Although the issue remained unresolved in the Council, the state was regularly discussed.
Recently, the renewed decisions took place, and on 14th June 2019, Council was informed of the state of play.
UK FTT - It is important to note that levying taxes on transactions is not new, for instance, the UK has been levying FTT in the form of stamp duty since 1964 with charges of 0.5% to the buyer of the stock.
This helped the government to raise about five billion euros during 1999-2000. Those who oppose FTT strongly argue that the taxing scheme is not adequate in counteracting speculative trading activities.
Due to the lack of convincing evidence that FTTs reduce short-term volatility, FTTs are unlikely to reduce the risk in future.
Swedish FTT - The Swedish FTT was applied during 1984-1991 in the hope of raking in additional tax revenue and reigning in financial markets. But, it is known to be a classic failure of FTT implementation.
Also, almost 50-basis-point tax on equity transactions levied by Sweden resulted in a migration of more than half of equity trading volume from Sweden to London. This proved itself to be a poor source of revenue and an inadequate mechanism to regulate the equity market.
Moreover, this article by BNY Mellon provides an overview of current implemented and proposed FTT legislation globally till 2018.
Regulations on Excessive Order Submissions and Cancellations
Now, we come to another regulatory change. It is the submissions and cancellations of a large number of orders in a very short amount of time, which are the most prominent characteristics of HFT.
It is important to note that charging a fee for high order-to-trade ratio traders has been considered to curb harmful behaviours of High Frequency Trading firms.
Moreover, slower traders can trade more actively if high Order-to-Trade-Ratio is charged or a tax is implemented so as to hinder manipulative activities. Such a tax should be able to improve liquidity in general.
According to Business Standard on 13th August 2019, the regulator is working on the concept of a “surge charge” on traders whose order-to-trade ratio is high.
Rebate Structures
Rebate Structures is another regulatory change. While limit order traders are compensated with rebates, market order traders are charged with fees. Thus, providing liquidity to the market as traders, often High Frequency Tradings, send the limit orders to make markets, which in turn provides for the liquidity on the exchange.
It is surely attractive to traders who submit a massive number of limit orders since the pricing scheme provides less risk to limit order traders.
There also exists an opposite fee structure to market-taker pricing called trader-maker pricing. It involves providing rebates to market order traders and charging fees to limit order traders is also used in certain markets.
Such structures are less favourable to high frequency traders in general and experts argue that these are often not very transparent markets, which can be detrimental for the markets.
Circuit Breakers
In order to prevent extreme market volatilities, circuit breakers are being used. Circuit Breakers are efficient in reducing market crashes.
To prevent market crash incidents like one in October 1987, NYSE has introduced circuit breakers for the exchange. This circuit breaker pauses market-wide trading when stock prices fall below a threshold.
Let us take a real-world example in the current scenario when, in the month of March, markets hit circuit breakers quite a lot of times because of the Coronavirus Outbreak. It led to the markets to halt for 15 minutes as the shares plunged.
On March 15, 2020, according to CNBC, The S&P 500 plunged about 8% right after the opening bell, tripping the level one circuit breaker that resulted in a trading halt for 15 minutes. The Dow Jones Industrial Average plummeted 2,250 points at the open. The market reopened at 9:46 a.m. ET.
Stocks ended up closing at their session lows after President Donald Trump said in a press conference that the worst of coronavirus could last until August and the developed economies “maybe” headed into a recession.
The Dow plummets 2,997 points, suffering its worst day since the “Black Monday” market crash in 1987. The S&P 500 ended the session down nearly 12%.
Structural Delays in Order Processing
A random delay in the processing of orders by certain milliseconds counteracts some HFT Strategies which supposedly tends to create an environment of the technology arms race and the winner-takes-all. You can explore the course on Millisecond trading.
Here, the advantage of faster traders declines significantly under random delays, while they still have the motivation to improve their trading speed. If benefits of improving trading speeds would diminish tremendously, it would discourage High Frequency Trading traders to engage in a fruitless arms race.
Going forward, we will see How HFT is Different from Long Term Investments?
High Frequency Trading vs Long-term Investments
There is a lot of debate and discussion that goes around comparing High Frequency Trading with Long Term Investments. It is important to mention here that there are various sentiments in the market from long term investors regarding HFT.
Instead of going into a debate of what is good or bad that is highly subjective, let us look at how HFT and Long Term Investment are different from each other.
HFT starts and ends with zero position in the market. The idea is to quickly buy and sell on very small margins to earn extremely small profits. Hence, the positions deployed by HFT are quite small. If a High Frequency Trader has to trade using 50 million cash, he/she would be taking a lot of positions, say 500 million, that is, almost 10 times of capital.
On the other hand, Long Term Investors start with a lot of capital to earn high profits over a long period of time. This requires large capital and results in higher transaction costs but also gives higher profit margins and consistency of profits is expected. The table below summarizes these points:
Contrasting High Frequency Trading and Long Term Investing
| Differences | High-Frequency Trading | Long Term Investing |
| Profit Margins | Small | Large |
| Transaction Costs | Small | Large |
| Capital Requirements | Large | Large (if earning for a living); can be small (if earning as a passive income) |
| Consistency of Profits | High | Low |
| Total Profit Potential | High | Large |
(Disclaimer: The table above is a general overview of both High Frequency Trading and Long Term Investing as well as analysis for some firms/institutions may vary with regard to the variables mentioned above.)
Wonderful! This brings us to the end of the article and surely we covered some of the most sought after topics on High Frequency Trading.
Now that you understand the history, basics, facts, features strategies, and careers in HFT, develop more skills and knowledge with this short video on Trading in Milliseconds that discusses MFT strategies and setup.
Conclusion
As we aimed at making this article informative enough to cater to the needs of all our readers, we have included almost all the concepts relating to High Frequency Trading and HFT algorithm.
If you're starting your journey in quantitative trading check out Quantra's course on Quantitative Trading Strategies and Models that teaches basic technical trading strategies, like the trend based strategy and the Bollinger bands strategy which can be traded on the live markets as well. Enroll now!
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.

