
Prerequisites
To fully grasp the bias-variance tradeoff and its role in trading, it is essential first to build a strong foundation in mathematics, machine learning, and programming.
Start with the fundamental mathematical concepts necessary for algorithmic trading by reading Stock Market Math: Essential Concepts for Algorithmic Trading. This will help you develop a strong understanding of algebra, arithmetic, and probability—critical elements in statistical modelling.
Since the bias-variance tradeoff is closely linked to regression models, go through Exploring Linear Regression Analysis in Finance and Trading to understand how regression-based predictive models work. To further strengthen your understanding, Linear Regression: Assumptions and Limitations explains common pitfalls in linear regression, which are directly related to bias and variance issues in model performance.
Since this blog focuses on a machine learning concept, it's crucial to start with the basics. Machine Learning Basics: Components, Application, Resources, and More introduces the fundamental aspects of ML, followed by Machine Learning for Algorithmic Trading in Python: A Complete Guide, which demonstrates how ML models are applied in financial markets.If you're new to Python, start with Basics of Python Programming. Additionally, the Python for Trading: Basic free course provides a structured approach to learning Python for financial data analysis and trading strategies.
This blog covers:
- Generating Random Values with a Uniform Distribution and Fitting Them to a Second-Order Equation
- Adding a Noise Component
- Splitting into Testing and Training Sets
- Fitting Four Different Models to the Data for Illustrating Bias and Variance
- Formal Discussion on Bias and Variance
- Change in Training and Testing Accuracy with Model Complexity
- Mathematical Treatment of Different Error Terms and Decomposition
- Values of the MSE, Bias, Variance, and Irreducible Error for the Simulated Data, and Their Intuition
Ice Breaker
Machine learning model creation is a tightrope walk. You create an easy model, and you end up with an underfit. Increase the complexity, and you end up with an overfitted model. What to do then? Well, that’s the agenda for this blog post. This is the first part of a two-blog series on bias-variance tradeoff and its use in market trading. We’ll explore the fundamental concepts in this first part and discuss the application in the second part.
Generating Random Values with a Uniform Distribution and Fitting Them to a Second-Order Equation
Let’s start with a simple illustration of underfitting and overfitting. Let’s take an equation and plot it. The equation is:
$$y = 2X^2 + 3X + 4$$When plotted, this is how it looks like:
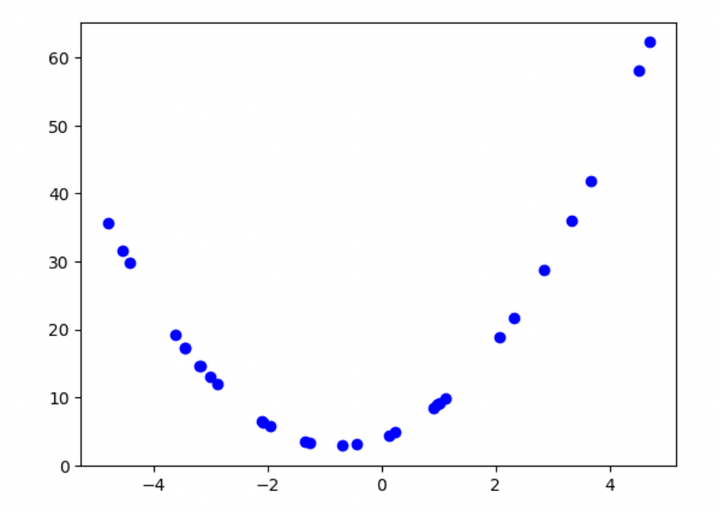
Figure 1: Plot of the second-order polynomial
Here’s the Python code for plotting the equation:
I have assigned random values to X, which range from -5 to 5 and belong to a uniform distribution. Suppose we are given only this scatter plot (not the equation). With some basic math knowledge, we could identify it as a second-order polynomial. We can even do this visually.
But in real settings, things aren’t that straightforward. Any data we gather or analyze will not form such a clear pattern, and there will be a random component. We term this random component as noise. To know more about noise, you can go through this blog article and also this one.
Adding a Noise Component
When we add a noise component to the above equation, this is how it looks like:
$$y = 2X^2 + 3X + 4 + noise$$What would its plot look like? Here you go:
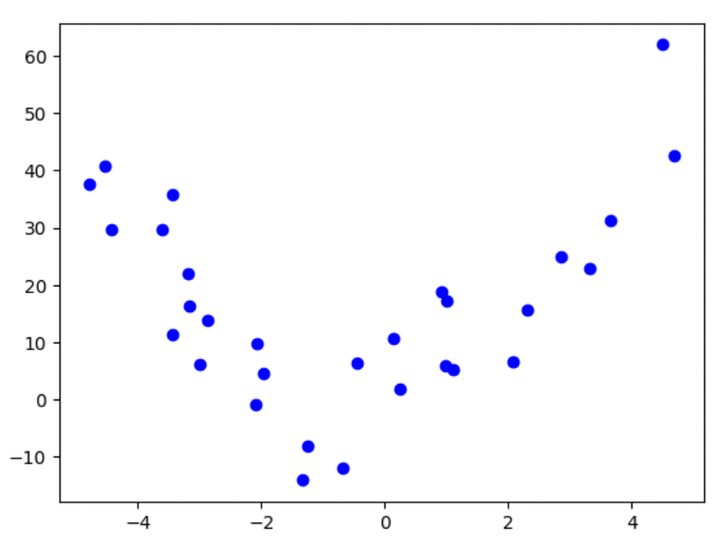
Figure 2: Plot of the second-order polynomial with noise
Do you think it’s as easily interpretable as the previous one? Maybe, since we only have 30 data points, the curve still looks somewhat second-orderish! But we’ll need a deeper analysis when we have many data points, and the underlying equation also starts getting more complex.
Here’s the code for generating the above data points and the plot from Figure 2:
Looking closely, you’ll realize that the noise component above belongs to a normal distribution, with mean = 0 and standard deviation = 10.
Splitting into Testing and Training Sets
Let’s now discuss the meaty part. We shall split the above data into train and test sets, with sizes of 20 and 10, respectively. If you aren’t conversant with these basic machine-learning concepts, I recommend skimming through this free book: ML for Trading.
This is what the data looks like after splitting:
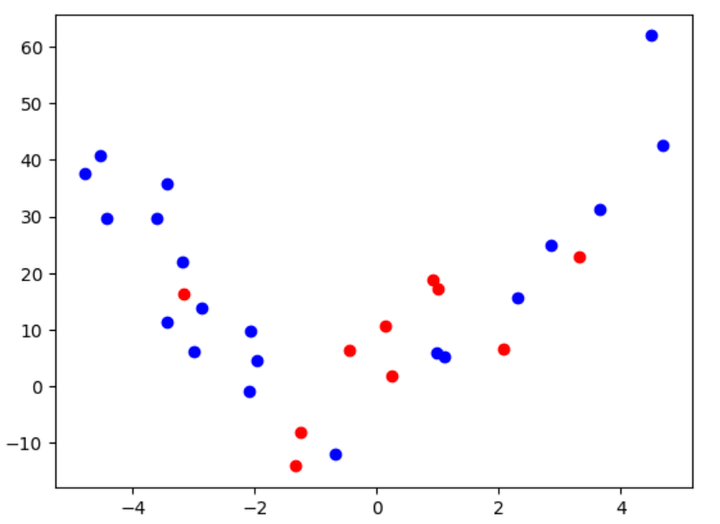
Figure 3: Plot of the second-order polynomial after splitting into train and test data
Here’s the code for the split and the above plot:
Fitting Four Different Models to the Data for Illustrating Bias and Variance
After splitting the data, we’ll train four different models with polynomials of order 1, 2, 3, and 10, respectively, and check their accuracies. We’ll do this by using linear regression. We’ll import the “PolynomialFeatures” and “LinearRegression” functionalities from different sub-modules of the scikit-learn library. Let’s see what the four models look like after we fit them on the data, with their respective accuracies:
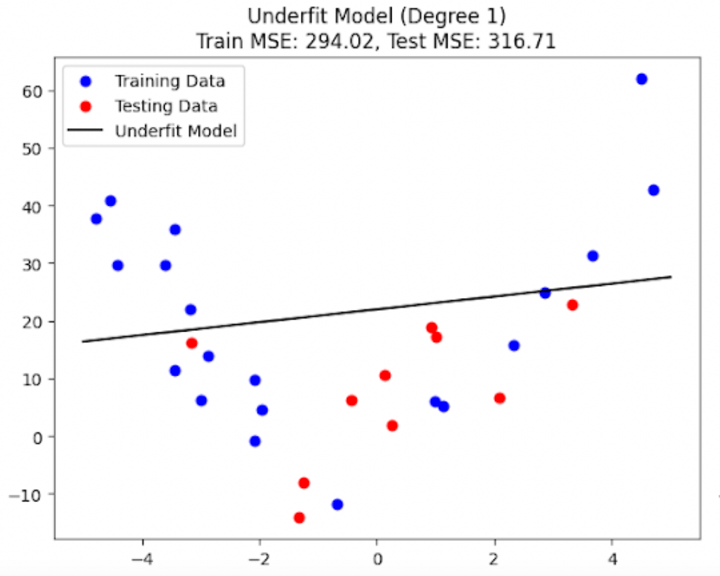
Figure 4a: Underfit model with high bias
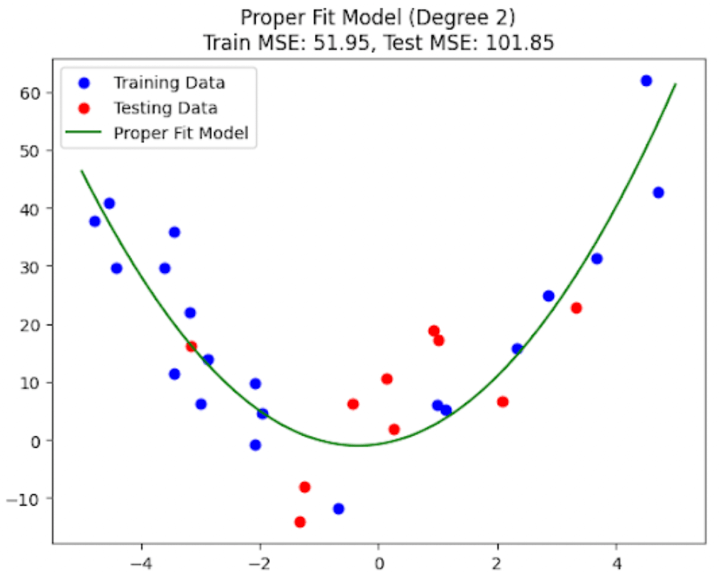
Figure 4b: Properly fit model with low bias and low variance (second order)
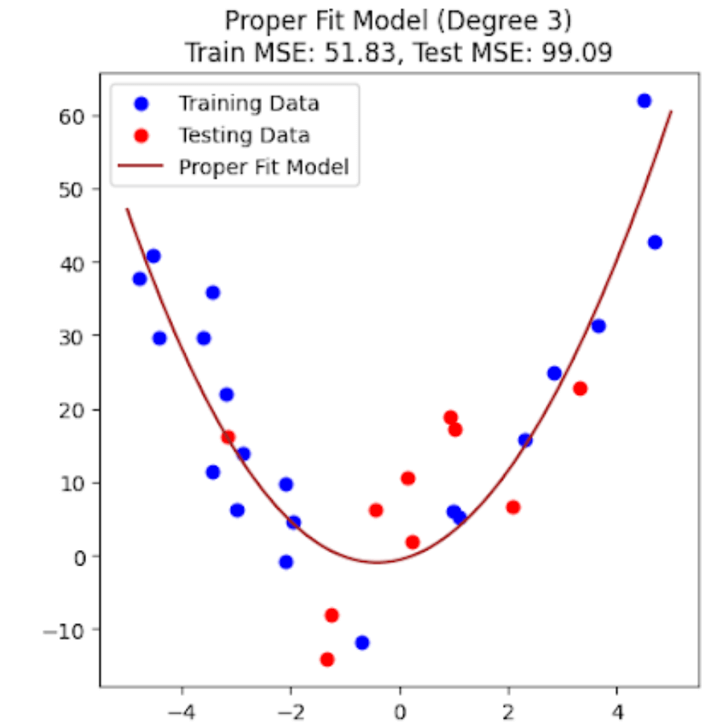
Figure 4c: Properly fit model with low bias and low variance (third order)
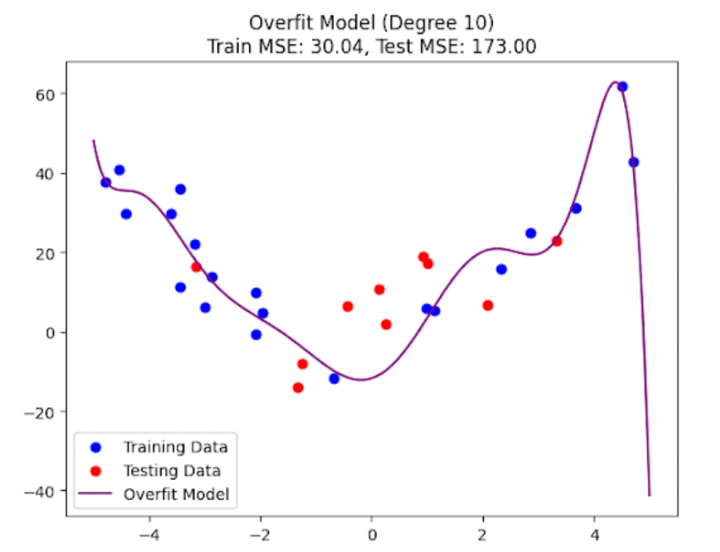
Figure 4d: Overfit model with high variance
The above four plots (Figure 4a to Figure 4d) should give you a clear picture of what it looks like when a machine learning model underfits, properly fits, and overfits on the training data. You might wonder why I’m showing you two plots (and thus two different models) for a proper fit. Don’t worry; I’ll discuss this in a couple of minutes.
For now, here’s the code for training the four models and for plotting them:
Formal Discussion on Bias and Variance
Let’s understand underfitting and overfitting better now.
Underfitting is also termed as “bias”. An underfit model doesn’t align with many points in the training data and carries on its own path. It doesn’t allow the data points to modify itself much. You can think of an underfit model as a person with a mind that’s mostly, if not wholly, closed to the ideas, methods, and opinions of others and always carries a mental bias toward things. An underfit model, or a model with high bias, is simplistic and can’t capture much essence or inherent information in the training data. Thus, it can not generalize well to the testing (unseen) data. Both the training and testing accuracies of such a model are low.
Overfitting is referred to as “variance”. In this case, the model aligns itself with most, if not all, data points in the training set. You can think of a model which overfits as a fickle-minded person who always sways on the opinions and decisions of others, and does not have any conviction of hertheir own. An overfit model, or a model with a high variance, tries to capture every minute detail of the training data, including the noise, so much so that it can’t generalize to the testing (unseen) data. In the case of a model with an overfit, the training accuracy is high, but the testing accuracy is low.
In the case of a properly fit model, we get low errors on both the training and testing data. For the given example, since we already know the equation to be a second-order polynomial, we should expect a second-order polynomial to yield the minimum testing and training errors. However, as you can see from the above results, the third-order polynomial model gives fewer errors on the training and the testing data. What’s the reason for this? Remember the noise term? Yup, that’s the primary reason for this discrepancy. What’s the secondary reason, then? The low number of data points!
Change in Training and Testing Accuracy with Model Complexity
Let’s plot the training and testing accuracies of all four models:
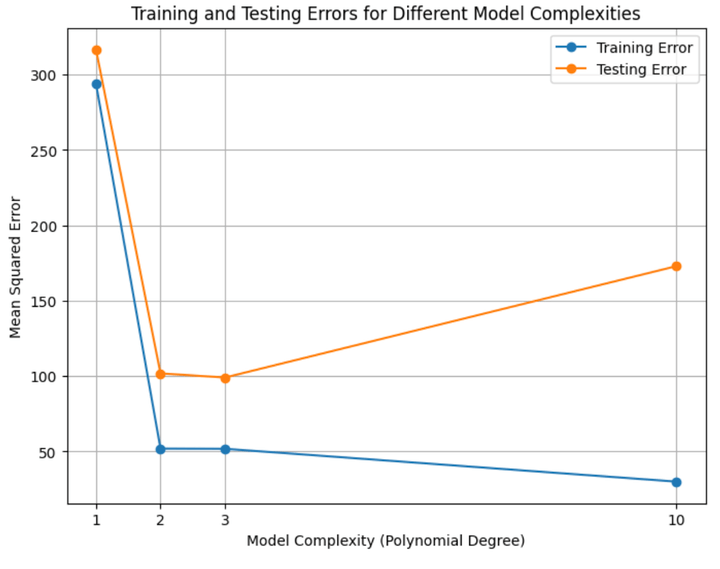
Figure 5: Training and testing errors for all the four models
From Figure 5 above, we can infer the following:
- The training and testing errors are pretty high for the underfit model.
- The training and testing errors are around the lowest for the proper fit model/s.
- The training error is low (even lower than the proper fit models), but the testing error is high.
- The testing error is higher than the training error in all cases.
Oh, and yes, here’s the code for the above calculation and the plots:
Mathematical Treatment of Different Error Terms and Decomposition
Now, with that out of the way, let’s proceed towards more mathematical definitions of bias and variance.
Let’s begin with the loss function. In machine learning parlance, the loss function is the function that we desire to minimize. Only after we get the least possible value of the loss function can we say that we have trained or fit the model well.
The mean square error (MSE) is one such loss function. If you’re familiar with the MSE, you’ll know that the lower the MSE, the more accurate the model.
The equation for the MSE is:
Thus,
$$MSE = Bias^2 + Variance$$
From the above equation, it is apparent that to reduce the error, we need to reduce either or both from bias and variance. However, since lowering either of these leads to a rise in the other, we need to develop a combination of both, which yields the minimum value for the MSE. So, if we do that and are lucky, can we end up with an MSE value of 0? Well, not quite! Apart from the bias and variance terms, there's another term that we need to add here. Owing to the inherent nature of any observed/recorded data, there is some noise in it, which comprises that part of the error we can't reduce. We term this part as the irreducible error. Thus, the equation for MSE becomes:
$$MSE = Bias^2 + Variance + Irreducible\;Error$$
Let's develop an intuition using the same simulated dataset as before.
We shall tweak the equation for MSE:
$$MSE = E[(\hat{y} - E[y])^2]$$
How and why did we do this? To get into the details, refer to Neural Networks and the Bias/Variance Dilemma" by Stuart German.
Basis the above paper, the equation for the MSE is:
$$MSE = E_D[(f(x; D) - E[y|x])^2]$$
where,
$$D\;is\;the\;training\;data,$$
$$E_D\;is\;the\;expected\;value\;with\;respect\;to\;the\;training\;data,$$
$$f(x; D)\;is\;the\;function\;of\;x,\;but\;with\;dependency\;on\;the\;training\;data,\;and,$$
$$E[y|x]\;is\;the\;the\;expected\;value\;of\;y\;when\;x\;is\;known.$$
Thus, the bias for each data point is the difference between the mean of all predicted values and the mean of all observed values. Quite intuitively, the lesser this difference, the lesser the bias, and the more accurate the model. But is it really so? Let's not forget that we increase the variance when we obtain a fit with a low bias.. How do we define the variance in mathematical terms? Here's the equation:
$$Variance = E[(\hat{y} - E[\hat{y}])^2]$$
The MSE comprises the above-defined bias and variance terms. However, since the MSE and variance terms are essentially squares of the differences between different y values, we must do the same to the bias term to ensure dimensional homogeneity.
Thus,
$$MSE = Bias^2 + Variance$$
From the above equation, it is apparent that to reduce the error, we need to reduce either or both from bias and variance. However, since lowering either of these leads to a rise in the other, we need to develop a combination of both, which yields the minimum value for the MSE. So, if we do that and are lucky, can we end up with an MSE value of 0? Well, not quite! Apart from the bias and variance terms, there's another term that we need to add here. Owing to the inherent nature of any observed/recorded data, there is some noise in it, which comprises that part of the error we can't reduce. We term this part as the irreducible error. Thus, the equation for MSE becomes:
$$MSE = Bias^2 + Variance + Irreducible\;Error$$
Let's develop an intuition using the same simulated dataset as before.
We shall tweak the equation for MSE:
$$MSE = E[(\hat{y} - E[y])^2]$$
How and why did we do this? To get into the details, refer to Neural Networks and the Bias/Variance Dilemma" by Stuart German.
Basis the above paper, the equation for the MSE is:
$$MSE = E_D[(f(x: D) - E[y|x])^2]$$
where,
$$D\;is\;the\;training\;data,$$
$$E_D\;is\;the\;expected\;value\;with\;respect\;to\;the\;training\;data,$$
$$f(x: D)\;is\;the\;function\;of\;x,\;but\;with\;dependency\;on\;the\;training\;data,\;and,$$
$$E[y|x]\;is\;the\;the\;expected\;value\;of\;y\;when\;x\;is\;known.$$
We won’t discuss anything more here since it is outside the scope of this blog article. You can refer to the paper cited above for a deeper understanding.
Values of the MSE, Bias, Variance, and Irreducible Error for the Simulated Data, and Their Intuition
We’ll also calculate the bias term and the variance term along with the MSE (using the tweaked formula mentioned above).. This is what the values look like for the testing data:
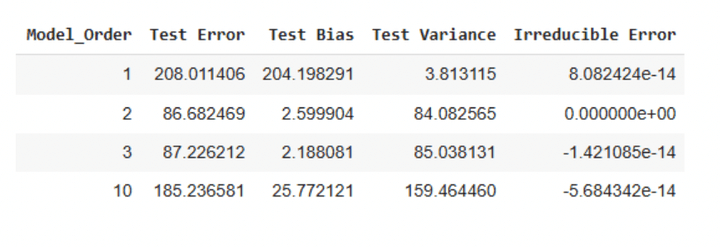
Table 1: Testing errors for simulated data
We can make the following observations from Table 1 above:
- The test errors are minimal for models with orders 2 and 3.
- The model with order 0 has the maximum bias term.
- The model with order 10 has the maximum variance term.
- The irreducible error is either 0 or negligible.
Here are the corresponding values for the training dataset:
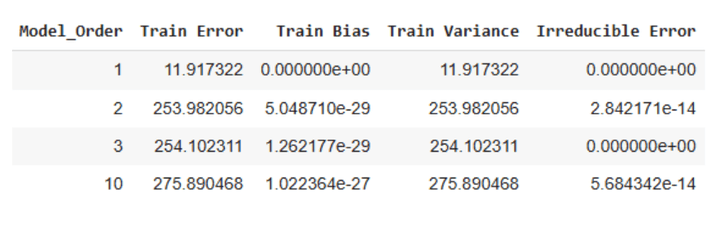
Table 2: Training errors for simulated data
We can make the following observations from Table 2 above:
- The training errors are higher for the three higher order models than the testing errors.
- The bias term is negligible for all four models.
- The error increases with increasing model complexity.
The above three discrepancies can be attributed to our data comprising only 20 train and 10 test data points. How, despite this data sampling, did we not get discrepancies in the test data error calculations? Well, for one, the test data remains unseen by the model, and the model tried to predict values based on what it learned during the training. Secondly, there is an inherent randomness when we work with such small samples, and we may have landed on the luckier side of things with the testing data. Thirdly, we did get a discrepancy, with the irreducible errors being almost 0 in the testing sample. Like I mentioned above, there is always an irreducible error owing to the inherent nature of any data. However, we got no such error since we used data that was simulated by using equations and did not use actual observed data.
The point of the above discussion is not to inspect the values that we got but to derive an intuition of the bias and variance terms. Hope you have a clear picture of these terms now. There’s another term called ‘decomposition’. It simply refers to the fact that we can ‘decompose’ the total error of any model into its error owing to bias, error owing to variance, and the inherent irreducible error.
Here’s the code for getting the above tables:
Till Next Time
Phew! That was a lot! We should stop here for now. In the second part, we’ll explore how to predict market prices and build trading strategies by employing bias-variance decomposition.
Next steps
Once you have built a solid foundation, you can explore more advanced applications of machine learning and regression in trading.
For those looking to enhance their Python skills, Python for Trading by Multi Commodity Exchange provides deeper insights into data handling, financial analysis, and strategy implementation using Python.
If you are interested in machine learning applications in trading, consider Machine Learning & Deep Learning in Trading. This learning track covers key aspects of ML, from data preprocessing and predictive modeling to AI model optimization, helping you implement classification and regression techniques in financial markets.
To take your regression-based trading strategies further, Trading with Machine Learning: Regression is an excellent resource. This course walks you through the step-by-step implementation of regression models for trading, including data acquisition, model training, testing, and prediction of stock prices.
For a structured approach to quantitative trading and machine learning, consider The Executive Programme in Algorithmic Trading (EPAT). This program covers classical ML algorithms (SVM, k-means clustering, decision trees, and random forests), deep learning fundamentals (neural networks and gradient descent), and Python-based strategy development. You’ll also explore statistical arbitrage using PCA, alternative data sources, and reinforcement learning for trading.
Once you've mastered these concepts, apply your knowledge in real-world trading using Blueshift, Blueshift is an all-in-one automated trading platform that brings institutional-class infrastructure for investment research, backtesting, and algorithmic trading to everyone, anywhere and anytime. It is fast, flexible, and reliable. It is also asset-class and trading-style agnostic. Blueshift helps you turn your ideas into investment-worthy opportunities.
File in the download:
- Bias Variance Decomposition - Python notebook
Feel free to make changes to the code as per your comfort.
All investments and trading in the stock market involve risk. Any decision to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.

